原文:
www.kdnuggets.com/2016/08/introduction-local-interpretable-model-agnostic-explanations-lime.html
作者:Marco Tulio Ribeiro、Sameer Singh^ 和 Carlos Guestrin。**
- 华盛顿大学
^ 加州大学欧文分校
机器学习是许多近期科学和技术进步的核心。随着计算机在围棋等游戏中战胜专业选手,许多人开始询问机器是否也会成为更好的司机甚至更好的医生。
在许多机器学习应用中,用户被要求信任模型来帮助他们做决策。医生肯定不会仅仅因为“模型说了”就对患者进行手术。即使在较低风险的情况下,例如从 Netflix 中选择一部电影观看,我们也需要一定程度的信任,然后才会根据模型的推荐花费几个小时的时间。尽管许多机器学习模型是黑箱模型,但了解模型预测背后的理由肯定会帮助用户决定是否信任这些预测。图 1 展示了一个例子,其中模型预测某位患者感染了流感。然后由一个“解释器”解释该预测,突出模型认为最重要的症状。通过了解模型背后的理由,医生现在可以决定是否信任模型——或不信任。
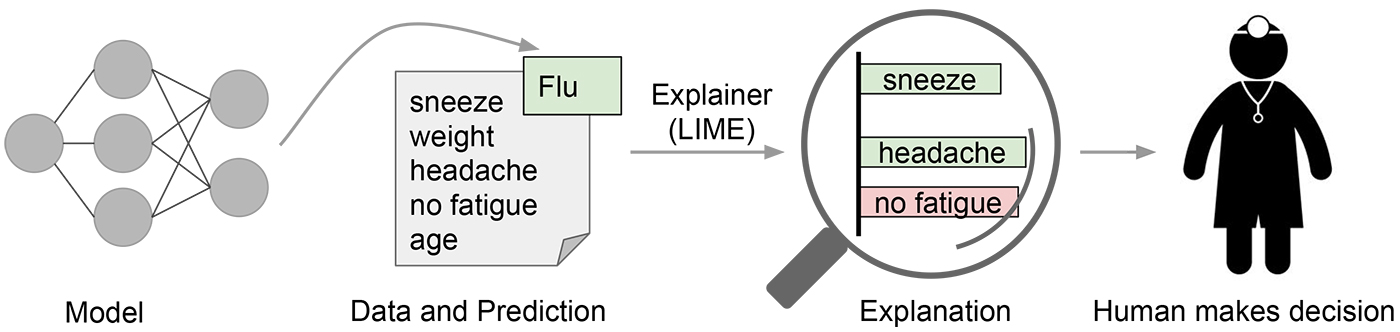
图 1. 向人类决策者解释个体预测。 来源:Marco Tulio Ribeiro。 从某种意义上说,每次工程师将机器学习模型上传到生产环境时,工程师都在隐含地信任该模型会做出合理的预测。这种评估通常是通过查看持出准确性或其他汇总指标来完成的。然而,正如任何曾经在实际应用中使用过机器学习的人都可以证明的那样,这些指标可能非常具有误导性。有时不应可用的数据意外地泄漏到训练和持出数据中(例如,提前查看未来)。有时模型会犯下令人尴尬的错误,这些错误是不可接受的。这些以及许多其他棘手的问题表明,在决定模型是否值得信赖时,理解模型的预测可能是一个额外有用的工具,因为人类通常拥有难以在评估指标中捕捉到的良好直觉和商业智慧。假设一个“选择步骤”,在这个步骤中选择某些具有代表性的预测以向人类解释,会使过程类似于图 2 所示的过程。

图 2. 向人类决策者解释模型。 来源:Marco Tulio Ribeiro。 在《我为什么应该信任你?解释任何分类器的预测》中,由Marco Tulio Ribeiro、Sameer Singh和Carlos Guestrin共同完成(即将在 ACM 的知识发现与数据挖掘会议上发表),我们准确地探讨了信任和解释的问题。我们提出了局部可解释模型无关解释(LIME)技术,这是一种解释任何机器学习分类器预测的方法,并评估其在与信任相关的各种任务中的有用性。
因为我们希望保持模型的独立性,所以我们可以通过扰动输入并观察预测结果的变化来学习基础模型的行为。这在可解释性方面是一种优势,因为我们可以通过改变对人类有意义的组件(例如,单词或图像的一部分)来扰动输入,即使模型使用的是更复杂的特征组件(例如,词嵌入)。
我们通过用可解释的模型(例如,只有少数非零系数的线性模型)来逼近潜在模型,从而生成解释,该模型是在原始实例的扰动上学习的(例如,删除单词或隐藏图像的部分)。LIME 的关键直觉在于,在我们要解释的预测的邻域内,用简单模型局部逼近黑箱模型比全局逼近要容易得多。这是通过根据扰动图像与我们要解释的实例的相似性来加权扰动图像来实现的。回到我们的流感预测示例,三种突出的症状可能是对黑箱模型的忠实近似,适用于与被检查的患者相似的患者,但它们可能并不代表模型对所有患者的行为。
请参见图 3,了解 LIME 在图像分类中的工作原理。假设我们想解释一个分类器,该分类器预测图像中包含树蛙的可能性。我们取左侧的图像,并将其划分为可解释的组件(连续超像素)。

*图 3. 将图像转化为可解释的组件。来源:Marco Tulio Ribeiro,Pixabay.*如图 4 所示,我们接着通过将一些可解释的组件“关闭”(在这种情况下,将其变为灰色)来生成一个扰动实例的数据集。对于每个扰动实例,我们根据模型获得图像中是否有树蛙的概率。然后,我们在这个数据集上学习一个简单的(线性)模型,该模型是局部加权的——也就是说,我们更关心在与原始图像更相似的扰动实例中犯错。最终,我们将具有最高正权重的超像素作为解释,其他部分则变灰。
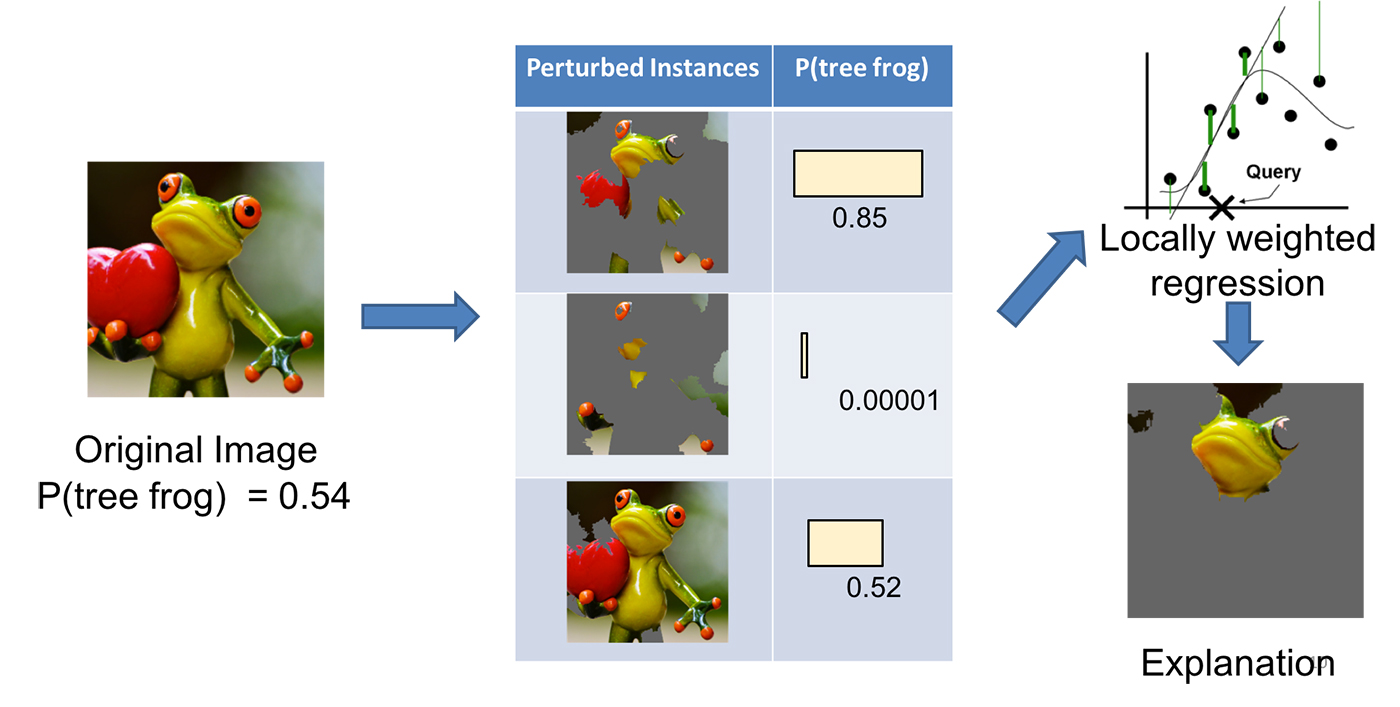
图 4. 使用 LIME 解释预测。来源:Marco Tulio Ribeiro,Pixabay.
我们使用 LIME 来解释各种分类器(例如,随机森林,支持向量机(SVM)以及神经网络)在文本和图像领域的结果。以下是一些生成的解释示例。
首先,一个文本分类的例子。著名的20 个新闻组数据集是该领域的一个基准,已被用来比较几篇论文中的不同模型。我们选择了两个难以区分的类别,因为它们共享许多词汇:基督教和无神论。通过训练一个拥有 500 棵树的随机森林,我们得到一个 92.4%的测试集准确率,这出乎意料地高。如果准确率是我们唯一的信任度衡量标准,我们肯定会信任这个分类器。然而,让我们看看图 5 中对测试集中任意实例的解释(使用我们的开源包的一行 Python 代码):
exp = explainer.explain_instance(test_example,
classifier.predict_proba, num_features=6)
*图 5. 20 个新闻组数据集中的预测解释。来源:Marco Tulio Ribeiro.*这是一个分类器正确预测实例但理由错误的案例。进一步探讨表明,单词“posting”(电子邮件头部的一部分)在训练集中的 21.6%的示例中出现,但在“基督教”类别中仅出现两次。在测试集中也是如此,单词几乎出现在 20%的示例中,但在“基督教”中仅出现两次。这种数据集中的伪影使得问题比实际情况简单得多,因为我们不会预期出现这样的模式。一旦理解了模型实际做了什么,这些见解就变得容易,这反过来又导致模型具有更好的泛化能力。
作为第二个例子,我们解释了Google 的 Inception 神经网络对任意图像的处理。在这种情况下,如图 6 所示,分类器预测“树蛙”是最可能的类别,其次是“台球桌”和“气球”,后者的概率较低。解释显示,分类器主要关注青蛙的面部作为预测类别的依据。它还揭示了为什么“台球桌”有非零概率:青蛙的手和眼睛与台球有相似之处,尤其是在绿色背景下。同样,心脏与红色气球也有相似之处。

*图 6. 对 Inception 预测的解释。前三个预测类别是“树蛙”、“台球桌”和“气球”。来源:马尔科·图利奥·里贝罗,Pixabay(青蛙,台球,热气球)。*在我们的研究论文中,我们展示了机器学习专家和普通用户如何从类似于图 5 和图 6 的解释中受益,并能够选择哪些模型具有更好的泛化能力,通过改变模型来改进模型,并获得对模型行为的关键见解。
信任对有效的人机互动至关重要,我们认为解释个体预测是评估信任的一种有效方式。LIME 是一个高效的工具,能够为机器学习从业者提供这种信任,并且是添加到他们工具箱中的不错选择(我们提到过我们有一个开源项目吗?),但仍然需要大量工作来更好地解释机器学习模型。我们对这个研究方向的前景感到兴奋。下面的视频提供了 LIME 的概述,更多细节请见我们的论文。
马尔科·图利奥·里贝罗 是华盛顿大学的博士生,师从卡洛斯·格斯特林。他的研究重点是让人们更容易理解和互动机器学习模型。
卡洛斯·格斯特林 是 Turi, Inc.的首席执行官,同时也是华盛顿大学计算机科学与工程系的亚马逊机器学习教授。作为机器学习领域公认的世界领袖,卡洛斯曾被《流行科学》杂志评为 2008 年“杰出 10 人”之一,因其对人工智能的贡献获得了 2009 年 IJCAI 计算机与思想奖,并获得了总统早期职业科学家和工程师奖(PECASE)。
萨米尔·辛格博士 是加州大学欧文分校计算机科学助理教授,从事大规模互动机器学习和自然语言处理的研究。
原文。经许可转载。
相关:
-
比赛获胜者:使用 Auto-sklearn 赢得 AutoML 挑战赛
-
接近(几乎)任何机器学习问题
-
TPOT:一个用于自动化数据科学的 Python 工具
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
 2. 谷歌数据分析专业证书 - 提升您的数据分析技能
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作