依然
ftp: ftp://public.sjtu.edu.cn/upload/lab6/
user:Dd_nirvana
password: public
使用make grade测试make handin生成压缩包
> git stash
> git fetch
> git checkout -b lab6 origin/new_lab6
> git checkout -b mylab6
> git merge mylab6 --no-commit
> vim GNUmakefile
> vim kern/syscall.c
> git add .
> git commit -m "manual merge mylab5 to lab6"
> git stash pop
这个lab需要实现网卡驱动,The card will be based on the Intel 82540EM chip, also known as the E1000.
然而这个驱动无法和真的互联网相连接,作者提供了网络堆栈和网络服务器。这个lab新的文件主要在net和kern文件夹里。
除了实现驱动,还要提供系统调用接口能够调用驱动,你还需要绑定很多东西到网络服务上,使用新的网络服务让你可以从文件系统获取文件。
很多设备驱动你需要从头开始写,该lab比以前的lab提供的指导少得多,没有骨架文件,没有具体的调用决策,大多让你自己设计。
我们将使用QEMU的用户模式网络堆栈,因为它不需要管理权限来运行。 QEMU的文档更多关于用户网。我们更新了makefile以启用QEMU的用户模式网络堆栈和虚拟E1000网卡。
默认情况下,QEMU提供了运行在IP 10.0.2.2上的虚拟路由器,并将为JOS分配IP地址10.0.2.15。为了保持简单,我们将这些默认值硬编码到net / ns.h中的网络服务器中。
虽然QEMU的虚拟网络允许JOS进行任意连接到Internet,但JOS的10.0.2.15地址在QEMU内部运行的虚拟网络(即,QEMU充当NAT)之外没有任何意义,因此我们无法直接连接到服务器运行在JOS中,甚至从运行QEMU的主机运行。为了解决这个问题,我们配置QEMU以在主机上的一些端口上运行服务器,该服务器只需连接到JOS中的某个端口,并在真实主机和虚拟网络之间往返穿梭数据。
您将在端口7(echo)和80(http)上运行JOS服务器。为了避免共享雅典娜机器上的冲突,makefile会根据您的用户ID生成这些转发端口。要了解QEMU在您的开发主机上转发哪些端口,请运行make哪些端口。为方便起见,makefile还提供make nc-7和make nc-80,可让您直接与终端上这些端口上运行的服务器进行交互。 (这些目标只连接到正在运行的QEMU实例;您必须单独启动QEMU本身。)
makefile还配置QEMU的网络堆栈,将所有传入和传出的数据包记录到您的实验室目录中的qemu.pcap。
要获取捕获数据包的十六进制/ ASCII转储,请使用tcpdump,如下所示:
tcpdump -XXnr qemu.pcap
或者,您可以使用Wireshark以图形方式检查pcap文件。
我们非常幸运地使用仿真硬件。 由于E1000以软件方式运行,仿真的E1000可以以用户可读的格式向我们报告其内部状态和遇到的任何问题。 一般来说,这样的奢侈品无法提供给开发商用裸机写作。
E1000可以产生大量调试输出,因此您必须启用特定的日志记录通道。 您可能会发现一些有用的渠道是:
| Flag | Meaning |
|---|---|
| tx | Log packet transmit operations |
| txerr | Log transmit ring errors |
| rx | Log changes to RCTL |
| rxfilter | Log filtering of incoming packets |
| rxerr | Log receive ring errors |
| unknown | Log reads and writes of unknown registers |
| eeprom | Log reads from the EEPROM |
| interrupt | Log interrupts and changes to interrupt registers. |
To enable "tx" and "txerr" logging, for example, use make E1000_DEBUG=tx,txerr ....
Note that E1000_DEBUG only works in the 6.828 version of QEMU. You can get this version of QEMU by git clone https://github.com/geofft/qemu.git -b 6.828-1.7.0
You can take debugging using software emulated hardware one step further. If you are ever stuck and do not understand why the E1000 is not responding the way you would expect, you can look at QEMU's E1000 implementation in hw/net/e1000.c
下载对应qemu,配置编译安装,设置新的qemu路径
> git clone https://github.com/geofft/qemu.git qemu-1.7.0 -b 6.828-1.7.0 --depth=1 && cd qemu-1.7.0
> ./configure --prefix=/home/oslab/qemu-1.7.0/dist --target-list="i386-softmmu"
> make && make install
> vim ../mit-jos/conf/env.mk从头实现网络堆栈很难,这里我们将用lwIP,lwIP is a black box that implements a BSD socket interface and has a packet input port and packet output port.
网络服务端由四部分组成
core network server environment (includes socket call dispatcher and lwIP)
input environment
output environment
timer environment
我们要实现的是文档中所给的图的绿色部分
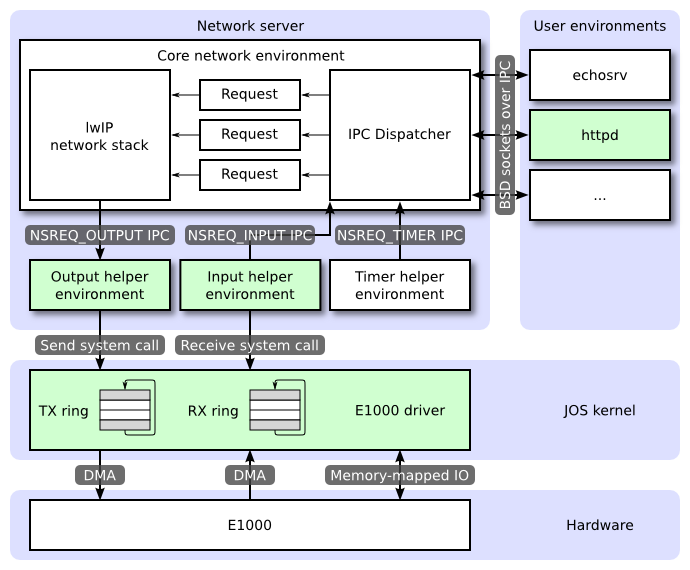
核心网络服务器环境由套接字调用分配器和lwIP本身组成。 套接字调用调度程序与文件服务器完全一样。 用户环境使用stubs(在lib / nsipc.c中找到)将IPC消息发送到核心网络环境。如果看看lib / nsipc.c,我们会发现核心网络服务器的方式与文件服务器相同:i386_init使用NS_TYPE_NS创建了NS环境,所以我们扫描envs,寻找这种特殊的环境类型。 对于每个用户环境IPC,网络服务器中的调度程序代表用户调用lwIP提供的适当的BSD套接字接口功能。
常规用户环境不直接使用nsipc_ *调用。 相反,他们使用lib / sockets.c中的函数,它提供了一个基于文件描述符的套接字API。 因此,用户环境通过文件描述符引用套接字,就像它们如何引用磁盘文件一样。 许多操作(connect,accpet等)特定于套接字,但read,write和close可以通过lib / fd.c中的普通文件描述符设备调度代码。 很像文件服务器为所有打开的文件维护内部唯一ID,lwIP还为所有打开的套接字生成唯一的ID。 在文件服务器和网络服务器中,我们使用存储在struct Fd中的信息将每个环境文件描述符映射到这些唯一的ID空间。
即使文件服务器和网络服务器的IPC调度程序看来似乎相同,但是有一个关键的区别。 BSD套接字调用如accept和recv可以无限期地阻止。 如果调度员让lwIP执行这些阻塞呼叫之一,则调度员也将阻塞,并且整个系统一次只能有一个未完成的网络呼叫。 由于这是不可接受的,网络服务器使用用户级线程来避免阻塞整个服务器环境。 对于每个传入的IPC消息,调度程序创建一个线程并处理新创建的线程中的请求。 如果线程阻塞,那么只有那个线程在其他线程继续运行时被置于休眠状态。
除了核心网络环境,还有三个帮助环境。 除了接受来自用户应用程序的消息外,核心网络环境的调度员还接受来自输入和定时器环境的消息。
在为用户环境套接字调用服务时,lwIP将生成用于网卡传输的数据包。 lwIP将使用NSREQ_OUTPUT IPC消息将每个要发送的数据包发送到输出帮助环境,报文附在IPC消息的页面参数中。 输出环境负责接收这些消息,并通过您即将创建的系统调用接口将数据包转发到设备驱动程序。
网卡接收到的数据包需要注入lwIP。 对于设备驱动程序接收到的每个数据包,输入环境将数据包从内核空间(使用您将实现的内核系统调用)提取出来,并使用NSREQ_INPUT IPC消息将数据包发送到核心服务器环境。
分组输入功能与核心网络环境分离,因为JOS使得很难同时接收IPC消息并轮询或等待来自设备驱动程序的分组。 我们在JOS中没有选择系统调用,允许环境监视多个输入源,以确定哪个输入已准备好处理。
如果你看看net/input.c和net/output.c,你会看到两者都需要实现。这主要是因为实现取决于你的系统调用接口。实现驱动程序和系统调用界面后,您将编写两个帮助环境的代码。
定时器环境周期性地向核心网络服务器发送类型为NSREQ_TIMER的消息,通知它定时器已过期。lwIP使用来自此线程的定时器消息来实现各种网络超时。
至此,文档介绍了图中几个部分的功能。
你的内核没有时间的概念,我们需要让它有。现在的时钟中断由硬件每10ms产生,在每一个时钟中断上我们可以对一个变量进行增加来记录过了10ms,这个东西被实现在kern/time.c中,但并没有完全整合到内核中。
在kern/trap.c中调用time_tick,实现sys_time_msec,并在kern/syscall.c中增加它让用户可以调用。
使用make INIT_CFLAGS=-DTEST_NO_NS run-testtime来测试,你应当看到环境从5s倒计数. The -DTEST_NO_NS disables starting the network server environment because it will panic at this point in the lab.
改动如下
diff --git a/kern/syscall.c b/kern/syscall.c
index 3591d20..a7def5d 100755
--- a/kern/syscall.c
+++ b/kern/syscall.c
@@ -399,8 +399,7 @@ syscall_wrapper(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint3
static int
sys_time_msec(void)
{
- // LAB 6: Your code here.
- panic("sys_time_msec not implemented");
+ return time_msec();
}
@@ -446,6 +445,8 @@ syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4,
return sys_ipc_try_send((envid_t)a1, (uint32_t)a2, (void *)a3, (unsigned)a4);
case SYS_ipc_recv:
return sys_ipc_recv((void *)a1);
+ case SYS_time_msec:
+ return sys_time_msec();
case NSYSCALLS:
default:
return -E_INVAL;
diff --git a/kern/trap.c b/kern/trap.c
index dc49edc..280d552 100644
--- a/kern/trap.c
+++ b/kern/trap.c
@@ -303,6 +303,7 @@ trap_dispatch(struct Trapframe *tf)
// Handle clock interrupts. Don't forget to acknowledge the
// interrupt using lapic_eoi() before calling the scheduler!
if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) {
+ time_tick();
lapic_eoi();
sched_yield();测试
> make INIT_CFLAGS=-DTEST_NO_NS run-testtime-nox
starting count down: 5 4 3 2 1 0说明成功,我看了一下user/testtime.c的代码确定不是我的问题让它陷入trap
编写驱动程序需要深入了解软件的硬件和界面。lab文档将提供如何与E1000进行接口的高级概述,但在编写驱动程序时需要大量使用英特尔手册。
Browse Intel's Software Developer's Manual for the E1000. This manual covers several closely related Ethernet controllers. QEMU emulates the 82540EM.
您现在应该仔细阅读第2章,以了解设备的感觉。要写你的driver,你需要熟悉第3章和第14章,以及4.1(尽管不是4.1的部分)。 您还需要使用第13章作为参考。 其他章节主要涵盖您的驱动程序不必与之进行交互的E1000的组件。 不要担心现在的细节; 只需了解文档的结构,以便稍后再找到它。
在阅读手册时,请记住,E1000是具有许多高级功能的复杂设备。 工作的E1000驱动程序只需要NIC提供的功能和接口的一小部分。 仔细想想最简单的方法来连接卡。 我们强烈建议您在使用高级功能之前,先获得基本的驱动程序。
E1000是一个PCI设备,意味着它插入主板上的PCI总线。 PCI总线具有地址,数据和中断线,并允许CPU与PCI设备和PCI设备进行通信,以读写内存。 需要先发现和初始化PCI设备才能使用。 发现是走PCI总线寻找连接设备的过程。 初始化是分配I / O和内存空间以及协商设备使用的IRQ线的过程。
我们为您提供了kern / pci.c中的PCI代码。 要在引导过程中执行PCI初始化,PCI代码将步行PCI总线寻找设备。 当它找到一个设备时,它会读取其供应商ID和设备ID,并使用这两个值作为键来搜索pci_attach_vendor数组。 该数组由struct pci_driver条目组成,如下所示:
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
如果发现设备的供应商ID和设备ID与阵列中的条目相匹配,则PCI代码将调用该条目的attachfn来执行设备初始化。(Devices can also be identified by class, which is what the other driver table in kern/pci.c is for.)
附加功能通过PCI函数进行初始化。 一个PCI卡可以暴露多种功能,尽管E1000仅暴露一种功能。 下面是我们如何在JOS中表示PCI功能:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
上述结构反映了开发者手册第4.1节表4-1中的一些条目。 结构pci_func的最后三个条目对我们特别感兴趣,因为它们记录了设备的协商存储器,I / O和中断资源。 reg_base和reg_size数组包含最多六个基地址寄存器或BAR的信息。reg_base存储内存映射I / O区域(或I / O端口资源的基本I / O端口)的基本内存地址,reg_size包含来自reg_base的相应基本值的字节数或I / O端口数,irq_line包含分配给设备的中断的IRQ行。E1000 BAR的具体含义见表4-2的下半部分。
当调用设备的附加功能时,设备已被发现但尚未启用。 这意味着PCI代码还没有确定分配给设备的资源,例如地址空间和IRQ行,因此,结构pci_func结构的最后三个元素尚未填写。附加函数应该调用 pci_func_enable,这将启用设备,协商这些资源,并填写结构pci_func。
实现附加功能初始化E1000。 在kern / pci.c中添加一个条目到pci_attach_vendor数组,以便在找到匹配的PCI设备时触发您的功能(请务必将其放在标记表结尾的{0,0,0}条目之前)。 您可以在第5.2节中找到QEMU模拟的82540EM的供应商ID和设备ID。 当引导时,JOS扫描PCI总线时,您还应该看到这些列表。
现在,只需通过pci_func_enable启用E1000设备。 我们将在整个实验室中添加更多的初始化。
我们为您提供了kern / e1000.c和kern / e1000.h文件,以便您不需要混淆构建系统。 您可能还需要将e1000.h文件包含在内核中的其他位置。
启动内核时,应该看到它打印出E1000卡的PCI功能被启用。 您的代码现在make grade应该通过pci附加测试。
然后我打开了kern/e1000.c和kern/e1000.h。。。。。技不如人甘拜下风
然后打开了mit所给的手册的5.2小节找到了我们要的82540EM-A 8086h 100E Desktop
代码修改如下
diff --git a/kern/e1000.c b/kern/e1000.c
index 7570e75..f637079 100644
--- a/kern/e1000.c
+++ b/kern/e1000.c
@@ -1,3 +1,6 @@
#include <kern/e1000.h>
-// LAB 6: Your driver code here
+int e1000_attach(struct pci_func *f) {
+ pci_func_enable(f);
+ return 0;
+};
diff --git a/kern/e1000.h b/kern/e1000.h
index e563ac4..ede9b50 100644
--- a/kern/e1000.h
+++ b/kern/e1000.h
@@ -1,4 +1,9 @@
#ifndef JOS_KERN_E1000_H
#define JOS_KERN_E1000_H
+#define Desktop_82540EM_A_Vendor_ID 0x8086
+#define Desktop_82540EM_A_Device_ID 0x100E
+
+#include <kern/pci.h>
+int e1000_attach(struct pci_func *f);
#endif // JOS_KERN_E1000_H
diff --git a/kern/pci.c b/kern/pci.c
index 42469fc..35825cc 100644
--- a/kern/pci.c
+++ b/kern/pci.c
@@ -30,6 +30,7 @@ struct pci_driver pci_attach_class[] = {
// pci_attach_vendor matches the vendor ID and device ID of a PCI device
struct pci_driver pci_attach_vendor[] = {
+ {Desktop_82540EM_A_Vendor_ID,Desktop_82540EM_A_Device_ID,&e1000_attach},
{ 0, 0, 0 },
};通过make grade得到输出pci attach: OK (6.1s)说明成功
这一部实现用于当有设备检测到8086 100E时也就是对应的设备时,将调用我们的中间函数再调用pci_func_enable(f)进行初始化结构体
软件通过内存映射I / O(MMIO)与E1000进行通信。您已经在JOS中看到过两次:CGA控制台和LAPIC都是通过写入和读取“内存”来控制和查询的设备。但这些读写不会去DRAM;他们直接去这些设备。
pci_func_enable使用E1000协商MMIO区域,并将其初始位置和大小存储在BAR 0中(即reg_base[0]和reg_size[0])。这是分配给设备的一系列物理内存地址,这意味着您必须通过虚拟地址进行访问。由于MMIO区域被分配了非常高的物理地址(通常高于3GB),所以由于JOS的256MB限制,您无法使用KADDR访问它。因此,您必须创建一个新的内存映射。这取决于你在哪里放这个映射。 BAR 0小于4MB,所以可以使用KSTACKTOP和KERNBASE之间的差距;或者可以将其映射到KERNBASE以上(但不要覆盖LAPIC使用的映射)。由于PCI设备初始化发生在JOS创建用户环境之前,因此您可以在kern_pgdir中创建映射,并始终可用。
在附加功能中,为E1000的BAR 0创建虚拟内存映射。由于这是设备内存而不是常规DRAM,因此您必须告诉CPU,缓存对该内存的访问是不安全的。幸运的是,页表为此提供了一些位;只需使用PTE_PCD | PTE_PWT(缓存禁用和write-trough)创建映射。 (如果对相关详细内容感兴趣, see section 10.5 of IA32 volume 3A.)
您将要记录在变量中进行此映射的位置,以便稍后访问您刚刚映射的寄存器。看看kern / lapic.c中的lapic变量的一个例子,一个方法来做到这一点。如果您使用指向设备寄存器映射的指针,请确保声明其为volatile;否则,允许编译器缓存值并重新排序对该内存的访问。
要测试映射,请尝试打印设备状态寄存器(第13.4.2节)。这是一个4字节寄存器,从寄存器空间的字节8开始。你应该得到0x80080783,这表明一个全双工链路在1000 MB / s以上。
提示:您需要很多常数,例如寄存器的位置和位掩码的值。 尝试从开发人员手册中复制这些错误是容易出错的,错误可能导致调试会话痛苦。 我们建议使用QEMU的e1000_hw.h作为指导。 我们不建议将它逐字地复制,因为它定义远远超过您实际需要,可能无法按需要的方式定义,但这是一个很好的起点。
在上面的qemu所提供的代码中对应的c和h分别变为hw/net/e1000.c和hw/net/e1000_regs.h,例如我上面定义的在这个h里是这样的定义的
#define E1000_DEV_ID_82540EM 0x100E
我们能在e1000_regs.h中找到#define E1000_STATUS 0x00008 /* Device Status - RO */
修改如下
kern/e1000.c增加
int e1000_attach(struct pci_func *f) {
pci_func_enable(f);
boot_map_region(kern_pgdir, E1000_BASE, f->reg_size[0], f->reg_base[0], PTE_PCD | PTE_PWT | PTE_W);
e1000 = (uint32_t *)E1000_BASE;
cprintf("E1000STATUS = %08x\n",e1000[E1000_STATUS >> 2]);
return 0;
};kern/e1000.h 增加
#define E1000_BASE KSTACKTOP
#define E1000_STATUS 0x00008 /* Device Status - RO */
#include <kern/pmap.h>
uint32_t *volatile e1000;kern/pmap.c修改
index fddcbd0..effd70a 100644
--- a/kern/pmap.c
+++ b/kern/pmap.c
@@ -71,7 +71,6 @@ static void check_page(void);
static int check_continuous(struct Page *pp, int num_page);
static void check_n_pages(void);
static void check_page_installed_pgdir(void);
-static void boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm);
static void boot_map_region_large(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm);
// This simple physical memory allocator is used only while JOS is setting
@@ -488,7 +487,7 @@ pgdir_walk(pde_t *pgdir, const void *va, int create)
// mapped pages.
//
// Hint: the TA solution uses pgdir_walk
-static void
+void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
int i;
diff --git a/kern/pmap.h b/kern/pmap.h
index 6dfeef8..29ccdb5 100644
--- a/kern/pmap.h
+++ b/kern/pmap.h
@@ -52,7 +52,7 @@ enum {
};
void mem_init(void);
-
+void boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm);
void page_init(void);
struct Page *page_alloc(int alloc_flags);
void page_free(struct Page *pp);运行make clean && make qemu-nox可以看到输出E1000STATUS = 80080783说明建立虚拟内存的映射成功
至此该网卡设备能够在被内核检测到时初始化,并能通过虚拟内存访问它
您可以想象通过从E1000的寄存器写入和读取来发送和接收数据包,但是这将很慢,并且需要E1000在内部缓冲数据包数据。 相反,E1000使用直接内存访问或DMA直接从内存读写数据包而不涉及CPU。 驱动程序负责为发送和接收队列分配内存,设置DMA描述符,并配置具有这些队列位置的E1000,但之后的所有内容都是异步的。 要传输数据包,驱动程序将其复制到发送队列中的下一个DMA描述符,并通知E1000另一个数据包可用; 当有时间发送数据包时,E1000会将数据复制到描述符之外。 同样,当E1000接收到一个数据包时,它将它复制到接收队列中的下一个DMA描述符,驱动程序可以在下一个机会读取它。
接收和发送队列和高层非常相似。 两者都由一系列描述符组成。 虽然这些描述符的确切结构有所不同,但每个描述符都包含一些标志和包含数据包数据的缓冲区的物理地址(要发送的卡的数据包数据,或由OS为该卡分配的缓冲区,以便将接收到的数据包写入)。
队列实现为循环队列,这意味着当card或driver到达队列的末尾时,它会回到开头。 两者都有头指针和尾指针,队列的内容是这两个指针之间的描述符。 硬件总是从头部消耗描述符并移动头指针,而驱动程序总是向尾部添加描述符并移动尾部指针。 发送队列中的描述符表示等待发送的数据包(因此,在steady状态下,发送队列为空)。 对于接收队列,队列中的描述符是卡可以接收数据包的自由描述符(因此,在steady状态下,接收队列由所有可用的接收描述符组成)。
指向这些数组的指针以及描述符中的数据包缓冲区的地址都必须是物理地址,因为硬件直接从物理RAM执行DMA,而不经过MMU。
E1000的发送和接收功能基本上是相互独立的,所以我们逐个实现。 我们将首先attack传输数据包,因为我们无法在不发送一个数据包的情况下测试接收。
首先,您必须按照第14.5节所述的步骤(您不必担心子部分)初始化card。 传输初始化的第一步是设置传输队列。 3.4节描述了队列的精确结构,第3.3.3节描述了描述符的结构。 我们不会使用E1000的TCP卸载功能,因此可以专注于“传统的传输描述符格式”。 您现在应该阅读这些部分,并熟悉这些结构。
您可以方便地使用C结构来描述E1000的结构。 正如你所看到的那样,像struct Trapframe这样的结构,C结构可以让你在内存中精确地布局数据。 C可以在字段之间插入填充,但E1000的结构布置成不应该是一个问题。 If you do encounter field alignment problems, look into GCC's "packed" attribute.
例如,考虑本手册表3-8中给出的传统传输描述符:
63 48 47 40 39 32 31 24 23 16 15 0
+---------------------------------------------------------------+
| Buffer address |
+---------------+-------+-------+-------+-------+---------------+
| Special | CSS | Status| Cmd | CSO | Length |
+---------------+-------+-------+-------+-------+---------------+
结构的第一个字节从右上方开始,因此要将其转换为C结构体,从右到左读取,从上到下。 如果你对照着右边,你会看到所有的字段都很适合标准大小的类型:
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
您的驱动程序必须为传输描述符数组和发送描述符指向的数据包缓冲区保留内存。 有几种方法可以做到这一点,从动态分配页面到在全局变量中简单地声明它们。 无论您选择什么,请记住,E1000直接访问物理内存,这意味着它访问的任何缓冲区必须在物理内存中是连续的。
还有多种方法来处理数据包缓冲区。 我们建议开始的最简单的方法是在驱动程序初始化期间为每个描述符保留一个分组缓冲区的空间,并简单地将数据包数据复制到这些预先分配的缓冲区中。 以太网数据包的最大大小为1518字节,这限制了这些缓冲区的大小。 更复杂的驱动程序可以动态分配分组缓冲区(例如,当网络使用量较低时减少内存开销),甚至通过由用户空间直接提供的缓冲区(一种称为“零拷贝”的技术),but it's good to start simple.
执行第14.5节所述的初始化步骤(但不是其子部分)。 使用第13节作为初始化过程参考的寄存器的参考,第3.3.3和3.4节用于引用发送描述符和发送描述符数组。
注意发送描述符数组的对齐要求以及该数组的长度限制。 由于TDLEN必须是128字节对齐,每个发送描述符是16字节,所以传输描述符数组将需要8个传输描述符的一些倍数。 但是,不要使用超过64个描述符,否则我们的测试将无法测试传输环溢出。
对于TCTL.COLD,您可以进行全双工操作。 对于TIPG,请参阅IEEE 802.3标准IPG第13.4.34节表13-77所述的默认值(不要使用第14.5节表中的值)。
31 30 29 20 19 10 9 0
Reserved IPGR2 IPGR1 IPGT
Try runningmake E1000_DEBUG=TXERR,TX qemu. You should see an "e1000: tx disabled" message when you set the TDT register (since this happens before you set TCTL.EN) and no further "e1000" messages.
看14.5的说明 其中最后的表见手册
/*
为发送描述符列表分配内存区域。软件应该保证这个内存在段落(16字节)边界上对齐。使用该区域的地址编程发送描述符基地址(TDBAL / TDBAH)寄存器。 TDBAL用于32位地址,TDBAL和TDBAH都用于64位地址。
将发送描述符长度(TDLEN)寄存器设置为描述符环的大小(以字节为单位)。该寄存器必须是128字节对齐。
在上电或软件启动的以太网控制器复位后,发送描述头和尾(TDH / TDT)寄存器被初始化(由硬件)为0b。软件应该向这两个寄存器写0b以确保这一点。
初始化发送控制寄存器(TCTL)以进行所需操作,包括以下内容:
•为了正常工作,将Enable(TCTL.EN)位设置为1b。
•将Pad Short Packets(TCTL.PSP)位设置为1b
•将碰撞阈值(TCTL.CT)配置为所需值。以太网标准为10h。此设置仅在半双工模式下有意义。
•将碰撞距离(TCTL.COLD)配置为其预期值。对于全双工操作,此值应设置为40h。对于千兆半双工,此值应设置为200h。对于10/100半双工,此值应设置为40h。
使用以下十进制值对发送IPG(TIPG)寄存器进行编程,以获得最小合法的数据包间隔:
[表=。= 文档说不要用这个表的值 要用13.4.34的表13-77的standard的]
IPGR1 and IPGR2 are not needed in full duplex, but are easier to always program to the values shown.
*/改动如下
diff --git a/kern/e1000.c b/kern/e1000.c
index d053e36..8bbd8e7 100644
--- a/kern/e1000.c
+++ b/kern/e1000.c
@@ -1,10 +1,35 @@
#include <kern/e1000.h>
+struct e1000_tx_desc tx_queue[E1000_NTX] __attribute__((aligned(16)));
+char tx_pkt_bufs[E1000_NTX][TX_PKT_SIZE];
+
int e1000_attach(struct pci_func *f) {
pci_func_enable(f);
boot_map_region(kern_pgdir, E1000_BASE, f->reg_size[0], f->reg_base[0], PTE_PCD | PTE_PWT | PTE_W);
e1000 = (uint32_t *)E1000_BASE;
assert(e1000[E1000_STATUS >> 2] == 0x80080783);
+
+ memset(tx_queue , 0, sizeof(tx_queue));
+ memset(tx_pkt_bufs, 0, sizeof(tx_pkt_bufs));
+ int i;
+ for (i = 0; i < E1000_NTX; i++) {
+ tx_queue[i].buffer_addr = PADDR(tx_pkt_bufs[i]);
+ tx_queue[i].upper.data |= E1000_TXD_STAT_DD;
+ }
+
+ e1000[E1000_TDBAL >> 2] = PADDR(tx_queue);
+ e1000[E1000_TDBAH >> 2] = 0;
+ e1000[E1000_TDLEN >> 2] = sizeof(tx_queue);
+ e1000[E1000_TDH >> 2] = 0;
+ e1000[E1000_TDT >> 2] = 0;
+
+ e1000[E1000_TCTL >> 2] |= E1000_TCTL_EN;
+ e1000[E1000_TCTL >> 2] |= E1000_TCTL_PSP;
+ e1000[E1000_TCTL >> 2] &= ~E1000_TCTL_CT; //0x000ff0
+ e1000[E1000_TCTL >> 2] |= (0x10) << 4; //0x000100
+ e1000[E1000_TCTL >> 2] &= ~E1000_TCTL_COLD;//0x3ff000
+ e1000[E1000_TCTL >> 2] |= (0x40) << 12; //0x012000
+ e1000[E1000_TIPG >> 2] = 10 | (4 << 10) | (6 << 20); // IPGT | IPGR1 | IPGR2
return 0;
}
diff --git a/kern/e1000.h b/kern/e1000.h
index c49d62b..b0dcb5b 100644
--- a/kern/e1000.h
+++ b/kern/e1000.h
@@ -6,11 +6,51 @@
#define E1000_BASE KSTACKTOP
+#define E1000_NTX 64
+#define TX_PKT_SIZE 1518
+
#define E1000_STATUS 0x00008 /* Device Status - RO */
+#define E1000_TDBAL 0x03800 /* TX Descriptor Base Address Low - RW */
+#define E1000_TDBAH 0x03804 /* TX Descriptor Base Address High - RW */
+#define E1000_TDLEN 0x03808 /* TX Descriptor Length - RW */
+#define E1000_TDH 0x03810 /* TX Descriptor Head - RW */
+#define E1000_TDT 0x03818 /* TX Descripotr Tail - RW */
+#define E1000_TCTL 0x00400 /* TX Control - RW */
+#define E1000_TIPG 0x00410 /* TX Inter-packet gap -RW */
+
+#define E1000_TCTL_EN 0x00000002 /* enable tx */
+#define E1000_TCTL_PSP 0x00000008 /* pad short packets */
+#define E1000_TCTL_CT 0x00000ff0 /* collision threshold */
+#define E1000_TCTL_COLD 0x003ff000 /* collision distance */
+
+#define E1000_TXD_STAT_DD 0x00000001 /* Descriptor Done */
+
+#include <inc/string.h>
#include <kern/pci.h>
#include <kern/pmap.h>
uint32_t *volatile e1000;
int e1000_attach(struct pci_func *f);
+/* Transmit Descriptor */
+struct e1000_tx_desc {
+ uint64_t buffer_addr; /* Address of the descriptor's data buffer */
+ union {
+ uint32_t data;
+ struct {
+ uint16_t length; /* Data buffer length */
+ uint8_t cso; /* Checksum offset */
+ uint8_t cmd; /* Descriptor control */
+ } flags;
+ } lower;
+ union {
+ uint32_t data;
+ struct {
+ uint8_t status; /* Descriptor status */
+ uint8_t css; /* Checksum start */
+ uint16_t special;
+ } fields;
+ } upper;
+};
+
#endif // JOS_KERN_E1000_H然而尝试了命令并没有看到disabled,在qemu的代码中grep到相关的输出语句。_(:з」∠)_,然后我发现忘了换qemu到1.7
现在,传输被初始化,你必须编写代码来传输数据包,并通过系统调用让用户空间可以访问它。 要发送数据包,您必须将其添加到发送队列的尾部,这意味着将数据包数据复制到下一个数据包缓冲区,然后更新TDT(发送描述符尾部)寄存器,以通知卡中有另一个数据包 传输队列。 (请注意,TDT是发送描述符数组的索引,而不是字节偏移;文档不是很清楚。)
但是,传输队列只有这么大。如果卡已经落后于传输数据包并且传输队列已满,会发生什么?为了检测这种情况,您将需要E1000的一些反馈信息。不幸的是,你不能只使用TDH(发送描述符头)寄存器;文档明确声明从软件读取该寄存器是不可靠的。但是,如果将RS位设置在发送描述符的命令字段中,那么当卡发送了该描述符中的数据包时,该卡将在描述符的状态字段中设置DD位。如果一个描述符的DD位被设置,你知道回收该描述符是安全的,并使用它来传输另一个数据包。
如果用户call传输函数,但是未设置下一个描述符的DD位,表示发送队列已满?你必须决定在这种情况下该怎么做。你可以简单地丢包。网络协议具有弹性,但如果丢弃了大量的数据包,协议可能无法恢复。您可以告诉用户环境必须重试,就像您对sys_ipc_try_send一样。这有利于产生数据的环境。您可以旋转驱动程序,直到发送描述符释放,但这可能会引起严重的性能问题,因为JOS内核不是设计为阻止。最后,您可以将发送环境置于休眠状态,并请求发送描述符释放时卡发送中断。我们建议您从最简单的想法开始。
Write a function to transmit a packet by checking that the next descriptor is free, copying the packet data into the next descriptor, and updating TDT. Make sure you handle the transmit queue being full.
现在是测试您的数据包传输代码的好时机。 尝试通过直接从内核调用传输功能来传输几个数据包。 您不必创建符合任何特定网络协议的数据包来测试。 运行make E1000_DEBUG=TXERR,TX qemu-nox来运行测试。 你应该看到类似的东西
int
e1000_transmit(char *data, int len){
if(data == NULL || len < 0 || len > TX_PKT_SIZE)
return -E_INVAL;
uint32_t tdt = e1000[E1000_TDT >> 2];
if(!(tx_queue[tdt].upper.data & E1000_TXD_STAT_DD))
return -E_TX_FULL;
memset(tx_pkt_bufs[tdt], 0 , sizeof(tx_pkt_bufs[tdt]));
memmove(tx_pkt_bufs[tdt], data, len);
tx_queue[tdt].lower.flags.length = len;
tx_queue[tdt].lower.data |= E1000_TXD_CMD_RS;
tx_queue[tdt].lower.data |= E1000_TXD_CMD_EOP;
tx_queue[tdt].upper.data &= ~E1000_TXD_STAT_DD;
e1000[E1000_TDT >> 2] = (tdt + 1) % E1000_NTX;
return 0;
}
在内核中添加
char test[100]="11111111";
e1000_transmit(test,5);
执行make E1000_DEBUG=TXERR,TX qemu-nox,看到输出e1000: index 0: 0x2c9420 : 5 0 说名成功
从这里我们可以看到,我们真实的操作是对硬件的储存位置的写,而这样做被qemu检测到了,也就完成了网络发送
当你传送数据包。 每行给出发送数组中的索引,发送描述符的缓冲区地址,cmd/CSO/length 和 special/CSS/status 字段。 如果QEMU不打印您从传输描述符中预期的值,请检查您是否填写正确的描述符,并正确配置了TDBAL和TDBAH。 如果您得到“e1000:TDH wraparound @ 0,TDT x,TDLEN y”消息,这意味着E1000一直运行在发送队列中,而不会停止(如果QEMU没有检查,则会进入无限循环) 这可能意味着您不是正确地操纵TDT。 如果你收到很多“e1000:tx disabled”消息,那么你没有设置发送控制寄存器。
一旦QEMU运行,您可以运行tcpdump -XXnr qemu.pcap查看您传输的数据包数据。 如果您看到来自QEMU的预期“e1000:index”消息,但是您的数据包捕获是空的,请仔细检查您是否填写了所有必填字段和位于传输描述符中的位置(E1000可能通过您的传输描述符,但没有 认为它必须发送任何东西)。
这要安装sudo apt-get install tcpdump.
我这里安装了tcpdump但并不能直接执行tcpdump要用/user/sbin/tcpdump。
Add a system call that lets you transmit packets from user space. The exact interface is up to you. Don't forget to check any pointers passed to the kernel from user space.
和其它的系统调用相同的位置加函数实现。
现在您有一个到设备驱动程序发送端的系统调用接口,现在是发送数据包的时候了。 输出辅助环境的目标是从核心网络服务器接收NSREQ_OUTPUT IPC消息,并使用上面添加的系统调用将伴随这些IPC消息的数据包发送到网络设备驱动程序。 NSREQ_OUTPUT IPC由net / lwip / jos / jif / jif.c中的low_level_output函数发送,它将lwIP堆栈粘贴到JOS的网络系统。 每个IPC将包括一个由union Nsipc组成的页面,其中包含在其结构jif_pkt pkt字段中(参见inc / ns.h)。 struct jif_pkt看起来像
struct jif_pkt {
int jp_len;
char jp_data[0];
};
jp_len表示数据包的长度。 IPC页面上的所有后续字节都专用于数据包内容。 在结构的末尾使用像jp_data这样的零长度数组是一个常见的C技巧(有些可以说可憎),用于表示没有预定长度的缓冲区。 由于C不会执行数组边界检查,只要确保结构体后面的足够的未使用的内存,就可以像使用jp_data一样是任何大小的数组。
当设备驱动程序的传输队列中没有更多空间时,请注意设备驱动程序,输出环境和核心网络服务器之间的交互。 核心网络服务器使用IPC将数据包发送到输出环境。 如果由于发送分组系统调用而导致输出环境暂停,因为驱动程序没有更多的新数据包的缓冲空间,核心网络服务器将阻止等待输出服务器接受IPC调用。
Implement net/output.c.
You can use net/testoutput.c to test your output code without involving the whole network server. Try running make E1000_DEBUG=TXERR,TX run-net_testoutput. You should see something like
Transmitting packet 0
e1000: index 0: 0x271f00 : 9000009 0
Transmitting packet 1
e1000: index 1: 0x2724ee : 9000009 0
...
and tcpdump -XXnr qemu.pcap should output
reading from file qemu.pcap, link-type EN10MB (Ethernet)
-5:00:00.600186 [|ether]
0x0000: 5061 636b 6574 2030 30 Packet.00
-5:00:00.610080 [|ether]
0x0000: 5061 636b 6574 2030 31 Packet.01
...
To test with a larger packet count, try make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput. If this overflows your transmit ring, double check that you're handling the DD status bit correctly and that you've told the hardware to set the DD status bit (using the RS command bit).
Your code should pass the testoutput tests of make grade.
diff --git a/inc/error.h b/inc/error.h
index f1a6651..5b55aeb 100644
--- a/inc/error.h
+++ b/inc/error.h
@@ -26,6 +26,9 @@ enum {
E_NOT_EXEC = 14, // File not a valid executable
E_NOT_SUPP = 15, // Operation not supported
+ // E1000 error codes
+ E_TX_FULL = 16, // Transfer queue is full
+
MAXERROR
};
diff --git a/inc/lib.h b/inc/lib.h
index 8632122..e256979 100644
--- a/inc/lib.h
+++ b/inc/lib.h
@@ -63,6 +63,7 @@ int sys_page_unmap(envid_t env, void *pg);
int sys_ipc_try_send(envid_t to_env, uint32_t value, void *pg, int perm);
int sys_ipc_recv(void *rcv_pg);
unsigned int sys_time_msec(void);
+int sys_net_try_send(char *data, int len);
// This must be inlined. Exercise for reader: why?
static __inline envid_t __attribute__((always_inline))
diff --git a/inc/syscall.h b/inc/syscall.h
index 5d18819..4c8c18d 100644
--- a/inc/syscall.h
+++ b/inc/syscall.h
@@ -23,6 +23,9 @@ enum {
SYS_sbrk,
SYS_time_msec,
+
+ SYS_net_try_send,
+
NSYSCALLS
};
diff --git a/kern/e1000.c b/kern/e1000.c
index 8bbd8e7..db2bab6 100644
--- a/kern/e1000.c
+++ b/kern/e1000.c
@@ -33,3 +33,24 @@ int e1000_attach(struct pci_func *f) {
e1000[E1000_TIPG >> 2] = 10 | (4 << 10) | (6 << 20); // IPGT | IPGR1 | IPGR2
return 0;
}
+
+int
+e1000_transmit(char *data, int len){
+ if(data == NULL || len < 0 || len > TX_PKT_SIZE)
+ return -E_INVAL;
+
+ uint32_t tdt = e1000[E1000_TDT >> 2];
+ if(!(tx_queue[tdt].upper.data & E1000_TXD_STAT_DD))
+ return -E_TX_FULL;
+
+ memset(tx_pkt_bufs[tdt], 0 , sizeof(tx_pkt_bufs[tdt]));
+ memmove(tx_pkt_bufs[tdt], data, len);
+ tx_queue[tdt].lower.flags.length = len;
+ tx_queue[tdt].lower.data |= E1000_TXD_CMD_RS;
+ tx_queue[tdt].lower.data |= E1000_TXD_CMD_EOP;
+ tx_queue[tdt].upper.data &= ~E1000_TXD_STAT_DD;
+
+ e1000[E1000_TDT >> 2] = (tdt + 1) % E1000_NTX;
+
+ return 0;
+}
diff --git a/kern/e1000.h b/kern/e1000.h
index b0dcb5b..cbd45b1 100644
--- a/kern/e1000.h
+++ b/kern/e1000.h
@@ -24,14 +24,19 @@
#define E1000_TCTL_COLD 0x003ff000 /* collision distance */
#define E1000_TXD_STAT_DD 0x00000001 /* Descriptor Done */
+#define E1000_TXD_CMD_EOP 0x01000000 /* End of Packet */
+#define E1000_TXD_CMD_RS 0x08000000 /* Report Status */
#include <inc/string.h>
+#include <inc/error.h>
#include <kern/pci.h>
#include <kern/pmap.h>
uint32_t *volatile e1000;
int e1000_attach(struct pci_func *f);
+int e1000_transmit(char *data, int len);
+
/* Transmit Descriptor */
struct e1000_tx_desc {
uint64_t buffer_addr; /* Address of the descriptor's data buffer */
diff --git a/kern/syscall.c b/kern/syscall.c
index a7def5d..fcbd7c0 100755
--- a/kern/syscall.c
+++ b/kern/syscall.c
@@ -13,6 +13,7 @@
#include <kern/sched.h>
#include <kern/time.h>
#include <kern/spinlock.h>
+#include <kern/e1000.h>
// Print a string to the system console.
// The string is exactly 'len' characters long.
@@ -381,6 +382,15 @@ sys_sbrk(uint32_t inc)
return curenv->env_heap_bottom = (uintptr_t)ROUNDDOWN(curenv->env_heap_bottom - inc,PGSIZE);
}
+// Returns 0 on success, < 0 on error.
+// Errors are:
+// -E_INVAL
+// -E_TX_FULL
+static int sys_net_try_send(char *data, int len) {
+ user_mem_assert(curenv, data, len, PTE_U); // check permission
+ return e1000_transmit(data, len);
+}
+
int32_t
syscall_wrapper(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5, struct Trapframe * tf)
{
@@ -447,6 +457,8 @@ syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4,
return sys_ipc_recv((void *)a1);
case SYS_time_msec:
return sys_time_msec();
+ case SYS_net_try_send:
+ return sys_net_try_send((char *) a1, (int) a2);
case NSYSCALLS:
default:
return -E_INVAL;
diff --git a/lib/syscall.c b/lib/syscall.c
index 42f269a..35e775f 100755
--- a/lib/syscall.c
+++ b/lib/syscall.c
@@ -144,3 +144,8 @@ sys_time_msec(void)
return (unsigned int) syscall(SYS_time_msec, 0, 0, 0, 0, 0, 0);
}
+int
+sys_net_try_send(char *data, int len)
+{
+ return syscall(SYS_net_try_send, 1, (uint32_t)data, (uint32_t)len, 0, 0, 0);
+}
diff --git a/net/output.c b/net/output.c
index f577c4e..2b77e3c 100644
--- a/net/output.c
+++ b/net/output.c
@@ -7,7 +7,19 @@ output(envid_t ns_envid)
{
binaryname = "ns_output";
- // LAB 6: Your code here:
- // - read a packet from the network server
- // - send the packet to the device driver
+ int r;
+ char *data;
+ int len;
+
+ while (1) {
+ if((r = sys_ipc_recv(&nsipcbuf)) < 0)
+ panic("%e",r);
+
+ if ((thisenv->env_ipc_from != ns_envid) || (thisenv->env_ipc_value != NSREQ_OUTPUT))
+ continue;
+
+ while((r = sys_net_try_send(nsipcbuf.pkt.jp_data, nsipcbuf.pkt.jp_len)) < 0)
+ if(r != -E_TX_FULL)
+ panic("%e", r);
+ }
}
权限位的设置的bug调了我好久最后把结构体换成qemu的e1000的结构体我才发现,所给的define的常量对于cmd/CSO/length这种要整个进行或而不是单独的一个项,绝望_(:з」∠)_
make grade得到35/35
就像发送数据包一样,您必须配置E1000接收数据包,并提供接收描述符队列并接收描述符。 3.2节描述了数据包接收如何工作,包括接收队列结构和接收描述符,初始化过程详见第14.4节。
阅读第3.2节。 您可以忽略关于中断和校验和卸载的任何内容(如果以后决定使用这些功能,则可以返回到这些部分),您不必关心阈值的细节以及卡内部缓存的工作原理。
14.4节
/*
使用所需的以太网地址编程接收地址寄存器(RAL / RAH)。应始终使用RAL [0] / RAH [0]来存储以太网控制器的以太网MAC地址。这可以来自EEPROM或任何其他方式(例如,在某些机器上,这来自系统PROM而不是适配器端口上的EEPROM)。
将MTA(组播表阵列)初始化为0b。根据软件,条目可以根据需要添加到此表中。
编程中断屏蔽设置/读取(IMS)寄存器,以使软件驱动程序想要在事件发生时被通知的任何中断。建议的位包括RXT,RXO,RXDMT,RXSEQ和LSC。没有直接的原因使能发送中断。
如果软件使用接收描述符最小阈值中断,接收延迟定时器(RDTR)寄存器应以所需的延迟时间进行初始化。
为接收描述符列表分配内存区域。软件应该保证这个内存在段落(16字节)边界上对齐。使用该区域的地址对接收描述符基地址(RDBAL / RDBAH)寄存器进行编程。 RDBAL用于32位地址,RDBAL和RDBAH都用于64位地址。
将接收描述符长度(RDLEN)寄存器设置为描述符环的大小(以字节为单位)。该寄存器必须是128字节对齐。
在上电或软件启动的以太网控制器复位后,接收描述符头和尾寄存器被初始化(由硬件)为0b。应分配适当大小的接收缓冲区,并将这些缓冲区的指针存储在接收描述符环中。软件使用适当的头尾地址初始化接收描述头(RDH)寄存器和接收描述符尾(RDT)。头应指向描述符中的第一个有效接收描述符,尾部应指向描述符环中最后一个有效描述符之外的一个描述符
使用适当的值编程接收控制(RCTL)寄存器,以获得所需的操作,以包括以下内容:
•将接收机使能(RCTL.EN)位设置为1b以进行正常操作。但是,最好将以太网控制器接收逻辑禁用(RCTL.EN = 0b),直到接收描述符环初始化并且软件准备好处理接收到的数据包为止。
•当处理大于标准以太网数据包大小的数据包时,将长数据包使能(RCTL.LPE)位设置为1b。例如,当处理巨型帧时,该位将被设置为1b。
•正常操作时,环回模式(RCTL.LBM)应设置为00b。
•将接收描述符最小阈值大小(RCTL.RDMTS)位配置为所需值。
•将组播偏移(RCTL.MO)位配置为所需值。
•将广播接受模式(RCTL.BAM)位设置为1b,允许硬件接受广播数据包。
•配置接收缓冲区大小(RCTL.BSIZE)位,以反映软件提供给硬件的接收缓冲区大小。如果接收缓冲区需要大于2048字节,则还要配置缓冲区扩展大小(RCTL.BSEX)位。
•如果要在将接收数据包传送到主机内存之前要求硬件剥离CRC,请设置Strip以太网CRC(RCTL.SECRC)位。
•对于82541xx和82547GI / EI,对中断屏蔽设置/读取(IMS)寄存器进行编程,以使所有发生均衡的驱动程序想要被通知的中断。建议的位包括RXT,RXO,RXDMT,RXSEQ和LSC。没有直接的原因使能发送中断。计划稍后优化中断,包括编程中断调节寄存器TIDV,TADV,RADV和IDTR。
•对于82541xx和82547GI / EI,如果软件使用接收描述符最小阈值中断,则接收延迟定时器(RDTR)寄存器应以所需的延迟时间进行初始化。
*/接收队列与发送队列非常相似,不同之处在于它包含等待填充传入数据包的空包缓冲区。因此,当网络空闲时,发送队列为空(因为已发送所有数据包),但接收队列已满(空包缓冲区)。
当E1000接收到数据包时,首先检查它是否匹配卡的配置过滤器(例如,查看该数据包是否寻址到该E1000的MAC地址),如果该数据包不匹配任何过滤器,则忽略该数据包。否则,E1000尝试从接收队列的头部检索下一个接收描述符。如果头(RDH)已经赶上尾部(RDT),则接收队列不在空闲描述符中,所以卡丢弃数据包。如果存在免费的接收描述符,则将数据包数据复制到描述符指向的缓冲区中,设置描述符的DD(描述符完成)和EOP(包结束)状态位,并增加RDH。
如果E1000在一个接收描述符中接收到大于分组缓冲区的分组,则它将从接收队列中检索尽可能多的描述符,以存储分组的全部内容。为了表明发生这种情况,它将在所有这些描述符上设置DD状态位,但只设置最后一个这些描述符的EOP状态位。您可以在驱动程序中处理这种可能性,或者只需将卡配置为不接受“长包”(也称为巨型帧),并确保您的接收缓冲区足够大以存储最大可能的标准以太网数据包(1518字节)。
设置接收队列,并按照第14.4节中的过程配置E1000。您不必支持“长数据包”或多播。现在,不要配置卡使用中断;如果您决定使用接收中断,您可以稍后更改。此外,配置E1000剥离以太网CRC,因为等级脚本期望它被剥离。
默认情况下,该卡将过滤所有数据包。您必须使用卡自己的MAC地址配置接收地址寄存器(RAL和RAH)才能接收到该卡的数据包。您可以简单地硬编码QEMU的默认MAC地址为52:54:00:12:34:56(我们已经在lwIP中进行了硬编码,所以在这里也不会使事情变得更糟)。要小心字节顺序; MAC地址从最低位字节写入高位字节,所以52:54:00:12是MAC地址的低位32位,34:56是高位16位。
E1000仅支持一组特定的接收缓冲区大小(在13.4.22中描述的RCTL.BSIZE中给出)。如果使您的接收数据包缓冲区足够大并禁用长数据包,则不必担心跨多个接收缓冲区的数据包。此外,请记住,就像传输一样,接收队列和数据包缓冲区在物理内存中必须是连续的。
make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput-nox
在做接受的时候需要注意的是,开的空间要足够,和发送不同,因为真实执行接受的是硬件,也就是当硬件发现分配空间不足,又有接受请求时,硬件会进行数据丢弃?!调了我好久好久。 以及为什么通过输出 发现接受的RDH的值变化和文档描述不完全一致,是因为超过了进行报错?[TODO]
需要注意的是需要实现 pgfault handler。因为它的使用量会超出一页了???? 为什么有两个点在没有pgfaulthandler 的情况下也能过。