You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
if(currentFirstChild!==null&¤tFirstChild.tag===HostText){// We already have an existing node so let's just update it and delete// the rest.deleteRemainingChildren(returnFiber,currentFirstChild.sibling);constexisting=useFiber(currentFirstChild,textContent,expirationTime);existing.return=returnFiber;returnexisting;}
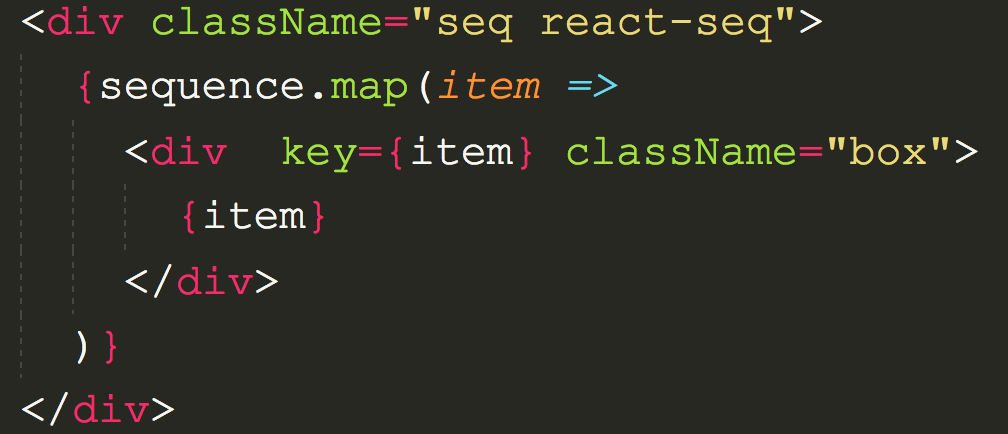
对于 Fragment 节点和一般的 Element 节点创建的方式不同,因为 Fragment 本来就是一个无意义的节点,他真正需要创建 Fiber 的是它的 children,而不是它自己,所以 createFiberFromFragment 传递的不是 element ,而是 element.props.children。
这是我 Deep In React 系列的第二篇文章,如果还没有读过的强烈建议你先读第一篇:详谈 React Fiber 架构(1)。
前言
我相信在看这篇文章的读者一般都已经了解过 React 16 以前的 Diff 算法了,这个算法也算是 React 跨时代或者说最有影响力的一点了,使 React 在保持了可维护性的基础上性能大大的提高,但 Diff 过程不仅不是免费的,而且对性能影响很大,有时候更新页面的时候往往 Diff 所花的时间 js 运行时间比 Rendering 和 Painting 花费更多的时间,所以我一直传达的观念是 React 或者说框架的意义是为了提高代码的可维护性,而不是为了提高性能的,现在所做的提升性能的操作,只是在可维护性的基础上对性能的优化。具体可以参考我公众号以前发的这两篇文章:
在上一篇将 React Fiber 架构中,已经说到过,React 现在将整体的数据结构从树改为了链表结构。所以相应的 Diff 算法也得改变,以为以前的 Diff 算法就是基于树的。
老的 Diff 算法提出了三个策略来保证整体界面构建的性能,具体是:
基于以上三个前提策略,React 分别对 tree diff、component diff 以及 element diff 进行算法优化。
具体老的算法可以见这篇文章:React 源码剖析系列 - 不可思议的 react diff
说实话,老的 Diff 算法还是挺复杂的,你仅仅看上面这篇文章估计一时半会都不能理解,更别说看源码了。对于 React 16 的 Diff 算法(我觉得都不能把它称作算法,最多叫个 Diff 策略)其实还是蛮简单的,React 16 是整个调度流程感觉比较难,我在前面将 Fiber 的文章已经简单的梳理过了,后面也会慢慢的逐个攻破。
接下来就开始正式的讲解 React 16 的 Diff 策略吧!
Diff 简介
做 Diff 的目的就是为了复用节点。
链表的每一个节点是 Fiber,而不是在 16 之前的虚拟DOM 节点。
Diff 就是新旧节点的对比,在上一篇中也说道了,这里面的 Diff 主要是构建 currentInWorkProgress 的过程,同时得到 Effect List,给下一个阶段 commit 做准备。
React16 的 diff 策略采用从链表头部开始比较的算法,是层次遍历,算法是建立在一个节点的插入、删除、移动等操作都是在节点树的同一层级中进行的。
对于 Diff, 新老节点的对比,我们以新节点为标准,然后来构建整个 currentInWorkProgress,对于新的 children 会有四种情况。
那么我们就来一步一步的看这四种类型是如何进行 diff 的。
前置知识介绍
这篇文章主要是从 React 的源码的逻辑出发介绍的,所以介绍之前了解下只怎么进入到这个 diff 函数的,react 的 diff 算法是从
reconcileChildren开始的reconcileChildren只是一个入口函数,如果首次渲染,current 空 null,就通过mountChildFibers创建子节点的 Fiber 实例。如果不是首次渲染,就调用reconcileChildFibers去做 diff,然后得出 effect list。接下来再看看 mountChildFibers 和 reconcileChildFibers 有什么区别:
他们都是通过
ChildReconciler函数来的,只是传递的参数不同而已。这个参数叫shouldTrackSideEffects,他的作用是判断是否要增加一些effectTag,主要是用来优化初次渲染的,因为初次渲染没有更新操作。reconcileChildFibers就是 Diff 部分的主体代码,这个函数超级长,是一个包装函数,下面所有的 diff 代码都在这里面,详细的源码注释可以见这里。参数介绍
returnFiber是即将 Diff 的这层的父节点。currentFirstChild是当前层的第一个 Fiber 节点。newChild是即将更新的 vdom 节点(可能是 TextNode、可能是 ReactElement,可能是数组),不是 Fiber 节点expirationTime是过期时间,这个参数是跟调度有关系的,本系列还没讲解,当然跟 Diff 也没有关系。前置知识介绍完毕,就开始详细介绍每一种节点是如何进行 Diff 的。
Diff TextNode
首先看 TextNode,因为它是最简单的,担心直接看到难的,然后就打击你的信心。
看下面两个小 demo:
对应的单链表结构图:
对于 diff TextNode 会有两种情况。
**为什么要分两种情况呢?**原因就是为了复用节点
第一种情况。xxx 是一个 TextNode,那么就代表这这个节点可以复用,有复用的节点,对性能优化很有帮助。既然新的 child 只有一个 TextNode,那么复用节点之后,就把剩下的 aaa 节点就可以删掉了,那么 div 的 child 就可以添加到 workInProgress 中去了。
源码如下:
在源码里
useFiber就是复用节点的方法,deleteRemainingChildren就是删除剩余节点的方法,这里是从currentFirstChild.sibling开始删除的。**第二种情况。**xxx 不是一个 TextNode,那么就代表这个节点不能复用,所以就从
currentFirstChild开始删掉剩余的节点,对应到上面的图中就是删除掉 xxx 节点和 aaa 节点。对于源码如下:
其中
createFiberFromText就是根据textContent来创建节点的方法。Diff React Element
有了上面 TextNode 的 Diff 经验,那么来理解 React Element 的 Diff 就比较简单了,因为他们的思路是一致的:先找有没有可以复用的节点,如果没有就另外创建一个。
那么就有一个问题,如何判断这个节点是否可以复用呢?
有两个点:1. key 相同。 2. 节点的类型相同。
如果以上两点相同,就代表这个节点只是变化了内容,不需要创建新的节点,可以复用的。
对应的源码如下:
相信这些代码都很好理解了,除了判断条件跟前面 TextNode 的判断条件不一样,其余的基本都一样,只是 React Element 多了一个跟新 ref 的过程。
同样,如果节点的类型不相同,就将节点从当前节点开始把剩余的都删除。
到这里,可能你们就会觉得接下来应该就是讲解当没有可以复用的节点的时候是如果创建节点的。
不过可惜你们猜错了。因为 Facebook 的工程师很厉害,另外还做了一个工作来优化,来找到复用的节点。
我们现在来看这种情况:
这种情况就是有可能更新的时候删除了一个节点,但是另外的节点还留着。
那么在对比 xxx 节点和 AAA 节点的时候,它们的节点类型是不一样,按照我们上面的逻辑,还是应该把 xxx 和 AAA 节点删除,然后创建一个 AAA 节点。
但是你看,明明 xxx 的 slibling 有一个 AAA 节点可以复用,但是被删了,多浪费呀。所以还有另外有一个策略来找 xxx 的所有兄弟节点中有没有可以复用的节点。
这种策略就是从 div 下面的所有子节点去找有没有可以复用的节点,而不是像 TextNode 一样,只是找第一个 child 是否可以复用,如果当前节点的 key 不同,就代表肯定不是同一个节点,所以把当前节点删除,然后再去找当前节点的兄弟节点,直到找到 key 相同,并且节点的类型相同,否则就删除所有的子节点。
对应的源码逻辑如下:
在上面这段代码我们需要注意的是,当 key 相同,React 会认为是同一个节点,所以当 key 相同,节点类型不同的时候,React 会认为你已经把这个节点重新覆盖了,所以就不会再去找剩余的节点是否可以复用。只有在 key 不同的时候,才会去找兄弟节点是否可以复用。
接下来才是我们前面说的,如果没有找到可以复用的节点,然后就重新创建节点,源码如下:
对于 Fragment 节点和一般的 Element 节点创建的方式不同,因为 Fragment 本来就是一个无意义的节点,他真正需要创建 Fiber 的是它的 children,而不是它自己,所以
createFiberFromFragment传递的不是element,而是element.props.children。Diff Array
Diff Array 算是 Diff 中最难的一部分了,比较的复杂,因为做了很多的优化,不过请你放心,认真看完我的讲解,最难的也会很容易理解,废话不多说,开始吧!
因为 Fiber 树是单链表结构,没有子节点数组这样的数据结构,也就没有可以供两端同时比较的尾部游标。所以React的这个算法是一个简化的两端比较法,只从头部开始比较。
前面已经说了,Diff 的目的就是为了复用,对于 Array 就不能像之前的节点那样,仅仅对比一下元素的 key 或者 元素类型就行,因为数组里面是好多个元素。你可以在头脑里思考两分钟如何进行复用节点,再看 React 是怎么做的,然后对比一下孰优孰劣。
1. 相同位置(index)进行比较
相同位置进行对比,这个是比较容易想到的一种方式,还是举个例子加深一下印象。
这已经是一个非常简单的例子了,div 的 child 是一个数组,有 AAA、BBB 然后还有其他的兄弟节点,在做 diff 的时候就可以从新旧的数组中按照索引一一对比,如果可以复用,就把这个节点从老的链表里面删除,不能复用的话再进行其他的复用策略。
那如果判断节点是否可以复用呢?有了前面的 ReactElement 和 TextNode 复用的经验,这个也类似,因为是一一对比嘛,相当于是一个节点一个节点的对比。
不过对于 newChild 可能会有很多种类型,简单的看下源码是如何进行判断的。
前面的经验可得,判断是否可以复用,常常会根据 key 是否相同来决定,所以首先获取了老节点的 key 是否存在。如果不存在老节点很可能是 TextNode 或者是 Fragment。
接下来再看 newChild 为不同类型的时候是如何进行处理的。
当 newChild 是 TextNode 的时候
如果 key 不为 null,那么就代表老节点不是 TextNode,而新节点又是 TextNode,所以返回 null,不能复用,反之则可以复用,调用
updateTextNode方法。当 newChild 是 Object 的时候
newChild 是 Object 的时候基本上走的就是 ReactElement 的逻辑了,判断 key 和 元素的类型是否相等来判断是否可以复用。
首先判断是否是对象,用的是
typeof newChild === 'object' && newChild !== null,注意要加!== null,因为typeof null也是 object。然后通过 $$typeof 判断是 REACT_ELEMENT_TYPE 还是 REACT_PORTAL_TYPE,分别调用不同的复用逻辑,然后由于数组也是 Object ,所以这个 if 里面也有数组的复用逻辑。
我相信到这里应该对于应该对于如何相同位置的节点如何对比有清晰的认识了。另外还有问题,那就是如何循环一个一个对比呢?
这里要注意,新的节点的 children 是虚拟 DOM,所以这个 children 是一个数组,而对于之前提到的老的节点树是链表。
那么循环一个一个对比,就是遍历数组的过程。
这并不是源码的全部源码,我只是把思路给贴出来了。
这是第一次遍历新数组,通过调用
updateSlot来对比新老元素,前面介绍的如何对比新老节点的代码都是在这个函数里。这个循环会把所以的从前面开始能复用的节点,都复用到。比如上面我们画的图,如果两个链表里面的 **???**节点,不相同,那么 newFiber 为 null,这个循环就会跳出。跳出来了,就会有两种情况。
2. 新节点已经遍历完毕
如果新节点已经遍历完毕的话,也就是没有要更新的了,这种情况一般就是从原来的数组里面删除了元素,那么直接把剩下的老节点删除了就行了。还是拿上面的图的例子举例,老的链表里**???还有很多节点,而新的链表???已经没有节点了,所以老的链表???**不管是有多少节点,都不能复用了,所以没用了,直接删除。
注意这里是直接
return了哦,没有继续往下执行了。3. 老节点已经遍历完毕
如果老的节点在第一次循环的时候就被复用完了,新的节点还有,很有可能就是新增了节点的情况。那么这个时候只需要根据把剩余新的节点直接创建 Fiber 就行了。
oldFiber === null就是用来判断老的 Fiber 节点变量完了的代码,Fiber 链表是一个单向链表,所以为 null 的时候代表已经结束了。所以就直接把剩余的 newChild 通过循环创建 Fiber。到这里,目前简单的对数组进行增、删节点的对比还是比较简单,接下来就是移动的情况是如何进行复用的呢?
4. 移动的情况如何进行节点复用
对于移动的情况,首先要思考,怎么能判断数组是否发生过移动操作呢?
如果给你两个数组,你是否能判断出来数组是否发生过移动。
答案是:老的数组和新的数组里面都有这个元素,而且位置不相同。
从两个数组中找到相同元素(是指可复用的节点),方法有很多种,来看看 React 是如何高效的找出来的。
把所有老数组元素按 key 或者是 index 放 Map 里,然后遍历新数组,根据新数组的 key 或者 index 快速找到老数组里面是否有可复用的。
这个
mapRemainingChildren就是将老数组存放到 Map 里面。元素有 key 就 Map 的键就存 key,没有 key 就存 index,key 一定是字符串,index 一定是 number,所以取的时候是能区分的,所以这里用的是 Map,而不是对象,如果是对象,属性是字符串,就没办法区别是 key 还是 index 了。现在有了这个 Map,剩下的就是循环新数组,找到 Map 里面可以复用的节点,如果找不到就创建,这个逻辑基本上跟
updateSlot的复用逻辑很像,一个是从老数组链表中获取节点对比,一个是从 Map 里获取节点对比。到这里新数组遍历完毕,也就是同一层的 Diff 过程完毕,接下来进行总结一下。
效果演示
以下效果动态演示来自于文章:React Diff 源码分析,我觉得这个演示非常的形象,有助于理解。
这里渲染一个可输入的数组。
当第一种情况,新数组遍历完了,老数组剩余直接删除(12345→1234 删除 5):
新数组没完,老数组完了(1234→1234567 插入 567):
移动的情况,即之前就存在这个元素,后续只是顺序改变(123 → 4321 插入4,移动2 1):
最后删除没有涉及的元素。
总结
对于数组的 diff 策略,相对比较复杂,最后来梳理一下这个策略,其实还是很简单,只是看源码的时候比较难懂。
我们可以把整个过程分为三个阶段:
updateSlot方法找到可以复用的节点,直到找到不可以复用的节点就退出循环。后记
刚开始阅读源码的过程是非常的痛苦的,但是当你一遍一遍的把作者想要表达的理解了,为什么要这么写 理解了,会感到作者的设计是如此的精妙绝伦,每一个变量,每一行代码感觉都是精心设计过的,然后感受到自己与大牛的差距,激发自己的动力。
更多的对于 React 原理相关,源码相关的内容,请关注我的 github:Deep In React 或者 个人博客:桃园
我是桃翁,一个爱思考的前端er,想了解关于更多的前端相关的,请关注我的公号:「前端桃园」
The text was updated successfully, but these errors were encountered: