Warning
This chapter is a draft, but feedback is already welcome.
In this chapter, we will create a basic optimization service that performs computations on a cluster rather than on the client side. This service can be extended with a straightforward frontend, allowing non-technical users to access the optimization capabilities. By encapsulating your optimization code within an easy-to-use API, integration into larger systems becomes more streamlined, and the separation of algorithm development from deployment is achieved.
While this chapter does not cover every aspect of building a production-ready API, it will address many important points of it. This foundational knowledge will enable you to collaborate effectively with your integration experts to finalize the implementation details, or even do it yourself.
To illustrate these principles, we will develop a simple optimization model for the Traveling Salesman Problem (TSP). Users will be able to submit an instance of the TSP, and the API will return a solution. The primary challenge, compared to many other APIs, is that the TSP is an NP-hard problem, and the CP-SAT solver may need several minutes to solve even moderately sized instances. Additionally, we cannot run the solver on the web server; instead, we must distribute the computation across a cluster. If many requests are received simultaneously, a request may need to wait before computation can start.
Therefore, this will not be a simple "send request, get response" API. Instead, we will implement a task queue, returning a task ID that users can use to check the status of their computation and retrieve the result once it is ready. To enhance user experience, we will allow users to specify a webhook URL, which we will call once the computation is complete.
You should be able to easily adapt this API to your own optimization problems, allowing you to quickly service your optimization algorithms to your colleagues.
Before we start coding, we should specify the endpoints our API will expose, so we know what we need to implement. This is something you can directly share with the coworkers who will implement the frontend or other parts of the system, so they know what to expect and can start working on their parts. It is usually simple to change the details of the payloads later, but changing the flow of the API can be much more complex.
The fundamental operations we will support are:
- POST /jobs: This endpoint will accept a JSON payload containing the TSP instance. The API will create a new task, store the instance, and return a task ID. The payload will also allow users to specify a webhook URL to call once the computation is complete.
- GET /jobs/{task_id}: This endpoint will return the status of the task with the given ID.
- GET /jobs/{task_id}/solution: This endpoint will return the solution of the task with the given ID, once it is available.
- DELETE /jobs/{task_id}: This endpoint will cancel the task with the given ID.
- GET /jobs: This endpoint will return a list of all tasks, including their status and metadata.
By defining these endpoints, we ensure that our API is robust and capable of handling the core functionalities required for managing and solving TSP instances. This structure will facilitate user interactions, from submitting tasks to retrieving solutions and monitoring the status of their requests.
Once we have successfully launched or TSP optimization service, we can
anticipate requests to extend our optimization capabilities to other problems.
Therefore, we should add the prefix /tsp_solver/v1 to all endpoints to
facilitate future expansions of our API with additional solvers, e.g.,
knapsack_solver/v1, or /tsp_solver/v2_experimental.
You may ask why we do not just create a new project for each solver and then just stick them together on a higher level. The reason is that we may want to share the same infrastructure for all solvers, especially the task queue and the worker cluster. This can not only be easier to maintain, but also cheaper as resources can be shared. Therefore, it makes sense to keep them in the same project. However, it will make sense to separate the actual algorithms from the API code, and only import the algorithms into our API project. We will not do this in this chapter, but I personally prefer the algorithms to be as separated as possible as they are often complex enough on their own.
Having outlined the requirements, we will now consider the architecture of our system. The system will incorporate the following components:
-
FastAPI for implementing the endpoints: FastAPI is a modern, high-performance web framework for building APIs with Python. We will use FastAPI to define API endpoints and handle HTTP requests due to its simplicity, speed, and automatic interactive API documentation.
-
Redis as a database and communication interface with the workers: Redis is an in-memory data structure store that can function as a database, cache, and message broker. We will utilize Redis for its speed and efficiency in storing and sharing tasks and solutions, which allows quick access and automatic expiration of data when it is no longer needed.
-
Workers managed with RQ (Redis Queue): RQ is a simple Python library for queuing jobs and processing them in the background with workers. This enables our API to handle tasks asynchronously, offloading computationally expensive processes to background workers and thereby improving the API's responsiveness.
To easily manage these components, we will use Docker and Docker Compose to containerize the API, Redis, and worker instances. This will allow us to quickly set up and run the service either locally or in a cloud environment.
Warning
We will ignore security aspects in this chapter. This service should be only for internal use within the own network and not be exposed to the internet. If you want to expose it, you should add authentication, rate limiting, and other security measures.
As we only have a single solver in this project, we will neither separate the solver from the API nor encapsulate the API, but use a simple, flat structure. You can find the complete project in ./examples/optimization_api.
├── app
│ ├── __init__.py
│ ├── config.py
│ ├── db.py
│ ├── main.py
│ ├── models.py
│ ├── solver.py
│ └── tasks.py
├── docker-compose.yml
├── Dockerfile
└── requirements.txt
Let us quickly go through the components of the project:
-
Requirements: We define the necessary Python packages in a
requirements.txtfile to ensure that the environment can be easily set up and replicated. This file includes all dependencies needed for the project.requirements.txtare rather outdated, but they are the simplest way to just install the dependencies in our container. -
Docker Environment:
Dockerfile: The Dockerfile specifies the Docker image and environment setup for the API. It ensures that the application runs in a consistent environment across different machines.docker-compose.yml: This file configures the services required for the project, including the API, Redis, and worker instances. Docker Compose simplifies the process of managing multiple containers, ensuring they are correctly built and started in the right order. A simpledocker-compose up -d --buildwill get the whole system up and running.
-
Solver Implementation:
./app/solver.py: This module contains the implementation of the TSP solver using CP-SAT. It also specifies the expected input and output data.
-
Request and Response Models:
./app/models.py: This module specifies further data models for API requests and responses.
-
Database:
./app/db.py: This module implements a proxy class to interact with Redis, abstracting database operations for storing and retrieving job requests, statuses, and solutions.
-
Config:
./app/config.py: This module provides configuration functions to set up the database connection and task queue. By centralizing configuration, we ensure that other parts of the application do not need to manage connection details, making the codebase more modular and easier to maintain.
-
Tasks:
./app/tasks.py: This module defines the tasks to be outsourced to workers, which right now only includes the optimization job. Our web server will only need to get a reference to the task functions in order to queue them, but not actually run anything of this code. For the workers, this file will be the entry point.
-
API:
./app/main.py: This module implements the FastAPI application with routes for submitting jobs, checking job statuses, retrieving solutions, and canceling jobs. This is the entry point for the web server.
To run the application, we use Docker and Docker Compose to build and run the containers. This ensures the API and its dependencies are correctly set up. Once the containers are running, you can interact with the API via HTTP requests.
We use Docker to ensure a consistent development and production environment.
Docker allows us to package our application with all its dependencies into a
standardized unit for software development. Docker Compose is used to manage
multi-container applications, defining and running multi-container Docker
applications. As the web server and the workers essentially share the same code,
just with different entry points, we can use the same Docker image for both. The
different entry points will be specified in the docker-compose.yml.
# Use an official Python runtime as a parent image
FROM python:3.12-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container at /app
COPY requirements.txt /
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r /requirements.txt
# Copy the current directory contents into the container at /app
COPY ./app /appTo get our composition of containers, with the API, Redis, and the workers up
and running, we use the following docker-compose.yml file:
services:
optimization_api_fastapi: # The web server
build: .
container_name: optimization_api_fastapi
ports: # exposing the API on port 80. Change this if you want to use a different port.
- "80:80"
depends_on: # Ensuring that the web server starts after the database.
- optimization_api_redis
command: python3 -m uvicorn main:app --host 0.0.0.0 --port 80 --reload
optimization_api_redis: # The database. We use the official Redis image.
image: redis:latest
container_name: optimization_api_redis
optimization_api_worker: # The worker
build: .
command: # Running this command will make our container a worker instead of a web server.
rq worker --with-scheduler --url redis://optimization_api_redis:6379/1
depends_on: # Ensuring that the worker starts after the database, as it needs to connect to it.
- optimization_api_redis
deploy:
replicas: 2 # Adding two workers for parallel processingThe docker-compose.yml file sets up three services:
optimization_api_fastapi: This service builds the FastAPI application, exposes it on port 80, and ensures it starts after Redis is available.optimization_api_redis: This service sets up the Redis database from the official Redis image. We just need to remember the name of the container to connect to it.optimization_api_worker: This service builds the worker, which processes tasks from the queue. We can scale the number of workers by increasing the number of replicas. Theoretically, these workers could be run on different machines to scale horizontally.
In this section, we will explore the implementation of the optimization
algorithm that we will deploy as an API. Specifically, we will focus on a simple
implementation of the Traveling Salesman Problem (TSP) using the add_circuit
constraint from the CP-SAT solver in OR-Tools.
The solver is the core component of our application, responsible for finding the optimal solution to the TSP instance provided by the user. The algorithm is implemented directly in the API project for simplicity. However, for more complex optimization algorithms, it is advisable to separate the algorithm into a distinct module or project. This separation facilitates isolated testing and benchmarking of the algorithm and improves the development process, especially when working in a team where different teams might maintain the API and the optimization algorithm.
# ./app/solver.py
from typing import Callable
from ortools.sat.python import cp_model
from pydantic import BaseModel, Field
# ---------------------------------------------------------------------
# A precise definition of the input and output data for the TSP solver.
# ---------------------------------------------------------------------
class DirectedEdge(BaseModel):
source: int = Field(..., ge=0, description="The source node of the edge.")
target: int = Field(..., ge=0, description="The target node of the edge.")
cost: int = Field(..., ge=0, description="The cost of traversing the edge.")
class TspInstance(BaseModel):
num_nodes: int = Field(
..., gt=0, description="The number of nodes in the TSP instance."
)
edges: list[DirectedEdge] = Field(
..., description="The directed edges of the TSP instance."
)
class OptimizationParameters(BaseModel):
timeout: int = Field(
default=60,
gt=0,
description="The maximum time in seconds to run the optimization.",
)
class TspSolution(BaseModel):
node_order: list[int] | None = Field(
..., description="The order of the nodes in the solution."
)
cost: float = Field(..., description="The cost of the solution.")
lower_bound: float = Field(..., description="The lower bound of the solution.")
is_infeasible: bool = Field(
default=False, description="Whether the instance is infeasible."
)
# ---------------------------------------------------------------------
# The TSP solver implementation using the CP-SAT solver from OR-Tools.
# ---------------------------------------------------------------------
class TspSolver:
def __init__(
self, tsp_instance: TspInstance, optimization_parameters: OptimizationParameters
):
self.tsp_instance = tsp_instance
self.optimization_parameters = optimization_parameters
self.model = cp_model.CpModel()
self.edge_vars = {
(edge.source, edge.target): self.model.new_bool_var(
f"x_{edge.source}_{edge.target}"
)
for edge in tsp_instance.edges
}
self.model.minimize(
sum(
edge.cost * self.edge_vars[(edge.source, edge.target)]
for edge in tsp_instance.edges
)
)
self.model.add_circuit(
[(source, target, var) for (source, target), var in self.edge_vars.items()]
)
def solve(self, log_callback: Callable[[str], None] | None = None):
solver = cp_model.CpSolver()
solver.parameters.max_time_in_seconds = self.optimization_parameters.timeout
if log_callback:
solver.parameters.log_search_progress = True
solver.log_callback = log_callback
status = solver.Solve(self.model)
if status in (cp_model.OPTIMAL, cp_model.FEASIBLE):
return TspSolution(
node_order=[
source
for (source, target), var in self.edge_vars.items()
if solver.value(var)
],
cost=solver.objective_value,
lower_bound=solver.best_objective_bound,
)
if status == cp_model.INFEASIBLE:
return TspSolution(
node_order=None,
cost=float("inf"),
lower_bound=float("inf"),
is_infeasible=True,
)
return TspSolution(
node_order=None,
cost=float("inf"),
lower_bound=solver.best_objective_bound,
)Tip
CP-SAT itself uses Protobuf for its input, output, and configuration. Having well-defined data models can help prevent many "garbage in, garbage out" issues and ease integration with other systems. It also facilitates testing and debugging, as you can simply serialize a specific scenario. For configuration, having default values is very helpful, as it allows you to extend the configuration without breaking backward compatibility. This can be a significant advantage, as you usually do not know all requirements upfront. Pydantic performs this job very well and can be used for the web API as well. Protobuf, while not Python-specific and therefore more versatile, is more complex to use and lacks the same flexibility as Pydantic.
In this section, we will define the request and response models for the API. These models will facilitate the communication between the client and the server by ensuring that the data exchanged is structured and validated correctly.
The models are defined in the models.py file and include the necessary data
structures for submitting a TSP job request and tracking the status of the job.
# ./app/models.py
"""
This file contains the implementation of additional data models for the optimization API.
"""
from datetime import datetime
from pydantic import BaseModel, HttpUrl, Field
from uuid import UUID, uuid4
from solver import OptimizationParameters, TspInstanceThe TspJobRequest model encapsulates the information required to submit a TSP
job to the API. It includes the TSP instance, optimization parameters, and an
optional webhook URL for notifications upon job completion.
class TspJobRequest(BaseModel):
"""
A request model for a TSP job.
"""
tsp_instance: TspInstance = Field(..., description="The TSP instance to solve.")
optimization_parameters: OptimizationParameters = Field(
default_factory=OptimizationParameters,
description="The optimization parameters.",
)
webhook_url: HttpUrl | None = Field(
default=None, description="The URL to call once the computation is complete."
)An request could look as follows:
{
"tsp_instance": {
"num_nodes": 4,
"edges": [
{"source": 0, "target": 1, "cost": 1},
{"source": 1, "target": 2, "cost": 2},
{"source": 2, "target": 3, "cost": 3},
{"source": 3, "target": 0, "cost": 4},
],
},
"optimization_parameters": {"timeout": 5},
"webhook_url": null,
},The TspJobStatus model is used to track the status of a TSP job. It provides
fields to monitor various stages of the job lifecycle, from submission to
completion.
class TspJobStatus(BaseModel):
"""
A response model for the status of a TSP job.
"""
task_id: UUID = Field(default_factory=uuid4, description="The ID of the task.")
status: str = Field(default="Submitted", description="The status of the task.")
submitted_at: datetime = Field(
default_factory=datetime.now, description="The time the task was submitted."
)
started_at: datetime | None = Field(
default=None, description="The time the task was started."
)
completed_at: datetime | None = Field(
default=None, description="The time the task was completed."
)
error: str | None = Field(
default=None, description="The error message if the task failed."
)These models ensure that the data exchanged between the client and the server is well-defined and validated.
In this section, we will implement a database proxy to store the tasks and solutions. For simplicity, we use Redis, which serves as both our database and task queue. This approach minimizes the need to set up additional databases and leverages Redis's key-value storage and automatic data expiration features.
The TspJobDbConnection class encapsulates the interactions with the Redis
database. It provides methods to register new jobs, update job statuses,
retrieve job requests, statuses, and solutions, list all jobs, and delete jobs.
# ./app/db.py
"""
This file contains a proxy class to interact with the database.
We are using Redis as the database for this example, but the implementation
can be easily adapted to other databases, as the proxy class abstracts the
database operations.
"""
import json
from models import TspJobStatus, TspJobRequest
from solver import TspSolution
from uuid import UUID
import redis
from typing import Optional, List
import loggingThe class is initialized with a Redis client and an expiration time for the
stored data. The _get_data method is a helper that retrieves and parses JSON
data from Redis by key.
class TspJobDbConnection:
def __init__(self, redis_client: redis.Redis, expire_time: int = 24 * 60 * 60):
"""Initialize the Redis connection and expiration time."""
self._redis = redis_client
self._expire_time = expire_time
logging.basicConfig(level=logging.INFO)
def _get_data(self, key: str) -> Optional[dict]:
"""Get data from Redis by key and parse JSON."""
try:
data = self._redis.get(key)
if data is not None:
return json.loads(data)
except redis.RedisError as e:
logging.error(f"Redis error: {e}")
return NoneThe get_request, get_status, and get_solution methods retrieve a TSP job
request, status, and solution, respectively, by their task ID.
def get_request(self, task_id: UUID) -> Optional[TspJobRequest]:
"""Retrieve a TSP job request by task ID."""
data = self._get_data(f"request:{task_id}")
return TspJobRequest(**data) if data else None
def get_status(self, task_id: UUID) -> Optional[TspJobStatus]:
"""Retrieve a TSP job status by task ID."""
data = self._get_data(f"status:{task_id}")
return TspJobStatus(**data) if data else None
def get_solution(self, task_id: UUID) -> Optional[TspSolution]:
"""Retrieve a TSP solution by task ID."""
data = self._get_data(f"solution:{task_id}")
return TspSolution(**data) if data else NoneThe set_solution method stores a TSP solution in Redis with an expiration
time. The register_job method registers a new TSP job request and status in
Redis.
def set_solution(self, task_id: UUID, solution: TspSolution) -> None:
"""Set a TSP solution in Redis with an expiration time."""
try:
self._redis.set(
f"solution:{task_id}", solution.model_dump_json(), ex=self._expire_time
)
except redis.RedisError as e:
logging.error("Redis error: %s", e)
def register_job(self, request: TspJobRequest) -> TspJobStatus:
"""Register a new TSP job request and status in Redis."""
job_status = TspJobStatus()
try:
pipeline = self._redis.pipeline()
pipeline.set(
f"status:{job_status.task_id}",
job_status.model_dump_json(),
ex=self._expire_time,
)
pipeline.set(
f"request:{job_status.task_id}",
request.model_dump_json(),
ex=self._expire_time,
)
pipeline.execute()
except redis.RedisError as e:
logging.error("Redis error: %s", e)
return job_statusThe update_job_status method updates the status of an existing TSP job. The
list_jobs method lists all TSP job statuses.
def update_job_status(self, job_status: TspJobStatus) -> None:
"""Update the status of an existing TSP job."""
try:
self._redis.set(
f"status:{job_status.task_id}",
job_status.model_dump_json(),
ex=self._expire_time,
)
except redis.RedisError as e:
logging.error("Redis error: %s", e)
def list_jobs(self) -> List[TspJobStatus]:
"""List all TSP job statuses."""
try:
status_keys = self._redis.keys("status:*")
data = self._redis.mget(status_keys)
return [TspJobStatus(**json.loads(status)) for status in data if status]
except redis.RedisError as e:
logging.error("Redis error: %s", e)
return []The delete_job method deletes a TSP job request, status, and solution from
Redis.
def delete_job(self, task_id: UUID) -> None:
"""Delete a TSP job request, status, and solution from Redis."""
try:
pipeline = self._redis.pipeline()
pipeline.delete(f"status:{task_id}")
pipeline.delete(f"request:{task_id}")
pipeline.delete(f"solution:{task_id}")
pipeline.execute()
except redis.RedisError as e:
logging.error("Redis error: %s", e)The database and task queue require a connection to be established before they
can be used. We provide get_db_connection and get_task_queue functions in
the config.py file for three primary reasons:
- To ensure that the database and task queue are properly set up with the correct connection details. If we change the Redis host, we only need to update it in one place.
- To integrate these functions into FastAPI's dependency injection system, ensuring that the database and task queue are available to the API endpoints without establishing the connection in each endpoint. This approach also facilitates testing with a different database.
- To allow both the FastAPI application and the workers to use the same configuration functions, despite having different entry points.
# ./app/config.py
"""
This file contains the configuration for the optimization API.
For this simple project, it only sets up the database connection and the task queue.
The other parts of the API should not be aware of the specific connection details.
"""
from db import TspJobDbConnection
import redis
from rq import Queue
def get_db_connection() -> TspJobDbConnection:
"""Provides a TspJobDbConnection instance."""
redis_client = redis.Redis(
host="optimization_api_redis", port=6379, decode_responses=True, db=0
)
return TspJobDbConnection(redis_client=redis_client)
def get_task_queue() -> Queue:
"""Provides a Redis Queue instance."""
redis_client = redis.Redis(host="optimization_api_redis", port=6379, db=1)
return Queue(connection=redis_client)With the database in place, we can create the tasks that will run the
optimization. The optimization will run in a separate process and use the
database to communicate with the web server. To keep things simple, we will pass
only the job reference to the task. The task will fetch the necessary data from
the database and update the database with the results. Additionally, by
including an if __name__ == "__main__": block, we allow the tasks to be run
via an external task queue as system commands.
The tasks.py file contains functions and logic for running the optimization
job in a separate worker process.
# ./app/tasks.py
"""
This file is responsible for running the optimization job in a separate worker.
"""
from config import get_db_connection
from models import TspJobRequest, TspJobStatus
from solver import TspSolver
from datetime import datetime
from uuid import UUID
from db import TspJobDbConnection
import httpx
import loggingThe send_webhook function sends a POST request to the specified webhook URL
with the job status. This allows for asynchronous notifications when the
computation is complete.
def send_webhook(job_request: TspJobRequest, job_status: TspJobStatus) -> None:
if job_request.webhook_url:
try:
# Send a POST request to the webhook URL
response = httpx.post(
url=f"{job_request.webhook_url}", json=job_status.model_dump_json()
)
response.raise_for_status() # Raise an error for bad responses
except httpx.HTTPStatusError as e:
logging.error(
f"HTTP error occurred: {e.response.status_code} - {e.response.text}"
)
except Exception as e:
logging.error(f"An error occurred: {e}")The run_optimization_job function fetches the job request from the database,
runs the optimization algorithm, and stores the solution back in the database.
It also updates the job status and sends a webhook notification upon completion.
def run_optimization_job(
job_id: UUID, db_connection: TspJobDbConnection | None = None
) -> None:
"""
Will fetch the job request from the database, run the optimization algorithm,
and store the solution back in the database. Finally, it will send a webhook
to the URL specified in the job. This function may be run on a separate worker,
which is why we do not pass or return data directly, but rather use the database.
"""
if db_connection is None:
db_connection = get_db_connection()
job_status = db_connection.get_status(job_id)
job_request = db_connection.get_request(job_id)
if job_status is None or job_request is None:
return # job got deleted
job_status.status = "Running"
job_status.started_at = datetime.now()
db_connection.update_job_status(job_status)
solver = TspSolver(job_request.tsp_instance, job_request.optimization_parameters)
solution = solver.solve(log_callback=print)
db_connection.set_solution(job_id, solution)
job_status.status = "Completed"
job_status.completed_at = datetime.now()
db_connection.update_job_status(job_status)
send_webhook(job_request, job_status)In this final section, we will build the actual API using FastAPI. This API will expose endpoints to submit TSP job requests, check job statuses, retrieve solutions, cancel jobs, and list all jobs. FastAPI provides an efficient and easy-to-use framework for building web APIs with Python.
The main.py file contains the FastAPI application setup and the API routes.
For simplicity, all routes are included in a single file, but in larger
projects, it is advisable to separate them into different modules.
# ./app/main.py
"""
This file contains the main FastAPI application.
For a larger project, we would move the routes to separate files, but for this example, we keep everything in one file.
"""
from uuid import UUID
from fastapi import FastAPI, APIRouter, HTTPException, Depends
from models import TspJobRequest, TspJobStatus
from solver import TspSolution
from config import get_db_connection, get_task_queue
from tasks import run_optimization_jobThe FastAPI application is initialized with a title and description. An API router is created to group the routes related to the TSP solver.
app = FastAPI(
title="My Optimization API",
description="This is an example on how to deploy an optimization algorithm based on CP-SAT as an API.",
)
tsp_solver_v1_router = APIRouter(tags=["TSP_solver_v1"])The post_job endpoint allows users to submit a new TSP job. The job is
registered in the database, and the optimization task is enqueued in the task
queue for asynchronous processing.
@tsp_solver_v1_router.post("/jobs", response_model=TspJobStatus)
def post_job(
job_request: TspJobRequest,
db_connection=Depends(get_db_connection),
task_queue=Depends(get_task_queue),
):
"""
Submit a new job to solve a TSP instance.
"""
job_status = db_connection.register_job(job_request)
# enqueue the optimization job in the task queue.
# Will return immediately, the job will be run in a separate worker.
task_queue.enqueue(
run_optimization_job,
job_status.task_id,
# adding a 60 second buffer to the job timeout
job_timeout=job_request.optimization_parameters.timeout + 60,
)
return job_statusThe get_job endpoint returns the status of a specific job identified by its
task ID.
@tsp_solver_v1_router.get("/jobs/{task_id}", response_model=TspJobStatus)
def get_job(task_id: UUID, db_connection=Depends(get_db_connection)):
"""
Return the status of a job.
"""
status = db_connection.get_status(task_id)
if status is None:
raise HTTPException(status_code=404, detail="Job not found")
return statusThe get_solution endpoint returns the solution of a specific job if it is
available.
@tsp_solver_v1_router.get("/jobs/{task_id}/solution", response_model=TspSolution)
def get_solution(task_id: UUID, db_connection=Depends(get_db_connection)):
"""
Return the solution of a job, if available.
"""
solution = db_connection.get_solution(task_id)
if solution is None:
raise HTTPException(status_code=404, detail="Solution not found")
return solutionThe cancel_job endpoint deletes or cancels a job. It does not immediately stop
the job if it is already running.
@tsp_solver_v1_router.delete("/jobs/{task_id}")
def cancel_job(task_id: UUID, db_connection=Depends(get_db_connection)):
"""
Deletes/cancels a job. This will *not* immediately stop the job if it is running.
"""
db_connection.delete_job(task_id)The list_jobs endpoint returns a list of all jobs and their statuses.
@tsp_solver_v1_router.get("/jobs", response_model=list[TspJobStatus])
def list_jobs(db_connection=Depends(get_db_connection)):
"""
List all jobs.
"""
return db_connection.list_jobs()Finally, we include the API router in the FastAPI application under the
/tsp_solver/v1 prefix.
app.include_router(tsp_solver_v1_router, prefix="/tsp_solver/v1")After you have run docker-compose up -d --build, you can access the API at
http://localhost:80/docs. This will open the Swagger UI, where you can test
the API. You can submit a job, check the status, and retrieve the solution. You
can also cancel a job or list all jobs.
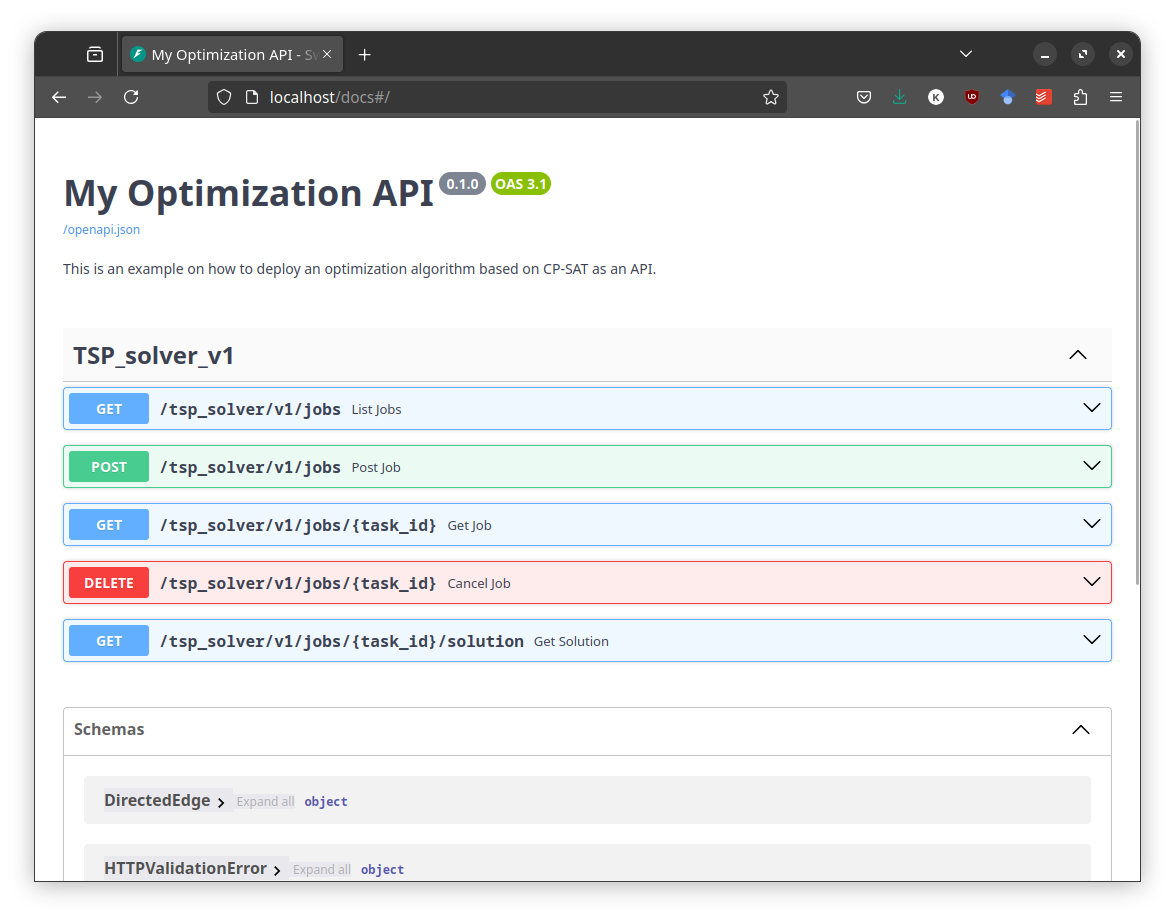 |
|---|
| FastAPI comes with a built-in Swagger UI that allows you to interact with the API. |
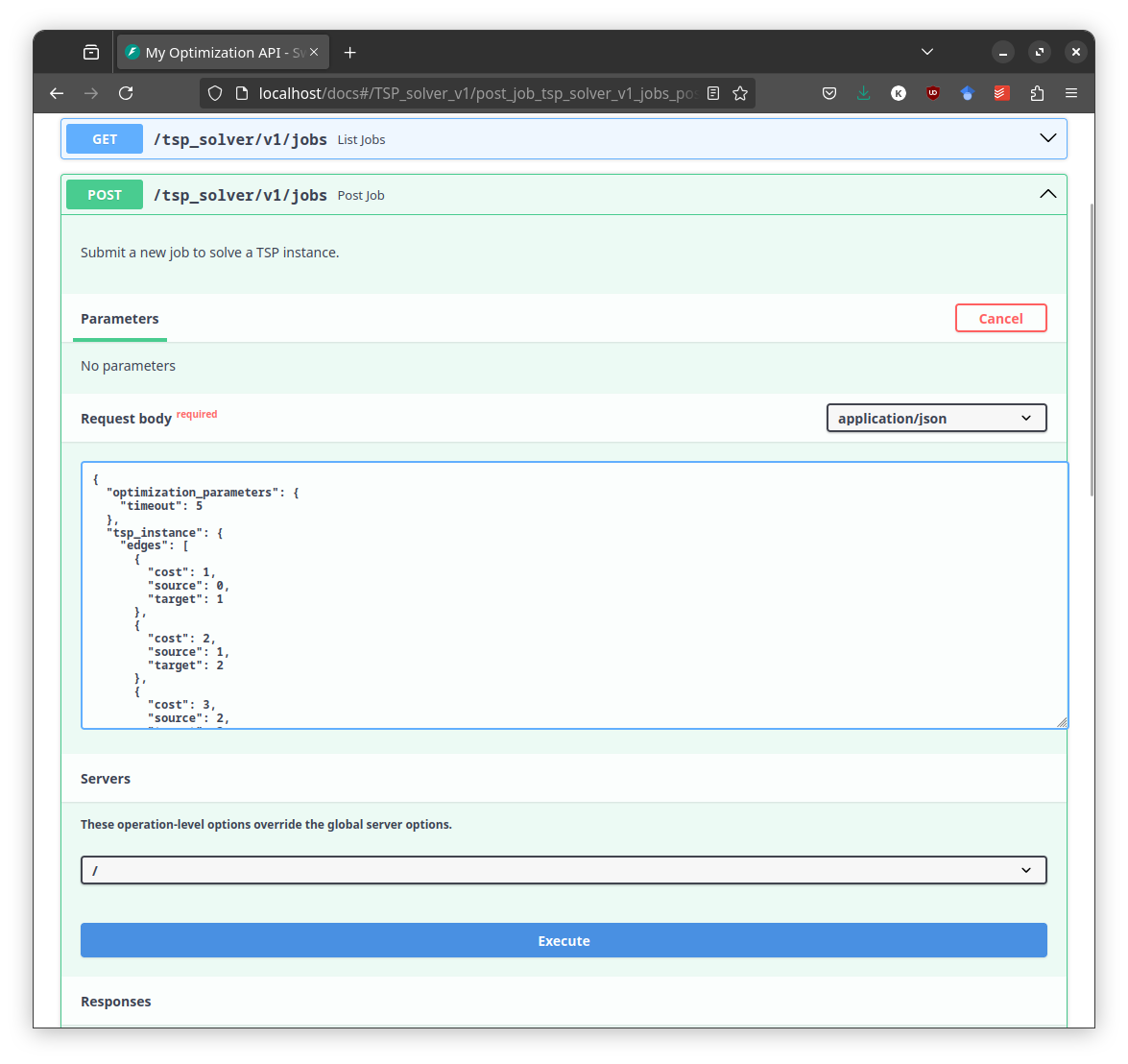 |
|---|
| By clicking on "try it out" you can directly submit a job to the API. |
Here is an instance to try it out
{
"optimization_parameters": {
"timeout": 5
},
"tsp_instance": {
"num_nodes": 15,
"edges": [
{ "source": 0, "target": 1, "cost": 82 },
{ "source": 1, "target": 0, "cost": 82 },
{ "source": 0, "target": 2, "cost": 35 },
{ "source": 2, "target": 0, "cost": 35 },
{ "source": 0, "target": 3, "cost": 58 },
{ "source": 3, "target": 0, "cost": 58 },
{ "source": 0, "target": 4, "cost": 9 },
{ "source": 4, "target": 0, "cost": 9 },
{ "source": 0, "target": 5, "cost": 13 },
{ "source": 5, "target": 0, "cost": 13 },
{ "source": 0, "target": 6, "cost": 91 },
{ "source": 6, "target": 0, "cost": 91 },
{ "source": 0, "target": 7, "cost": 72 },
{ "source": 7, "target": 0, "cost": 72 },
{ "source": 0, "target": 8, "cost": 16 },
{ "source": 8, "target": 0, "cost": 16 },
{ "source": 0, "target": 9, "cost": 50 },
{ "source": 9, "target": 0, "cost": 50 },
{ "source": 0, "target": 10, "cost": 80 },
{ "source": 10, "target": 0, "cost": 80 },
{ "source": 0, "target": 11, "cost": 92 },
{ "source": 11, "target": 0, "cost": 92 },
{ "source": 0, "target": 12, "cost": 28 },
{ "source": 12, "target": 0, "cost": 28 },
{ "source": 0, "target": 13, "cost": 17 },
{ "source": 13, "target": 0, "cost": 17 },
{ "source": 0, "target": 14, "cost": 97 },
{ "source": 14, "target": 0, "cost": 97 },
{ "source": 1, "target": 2, "cost": 14 },
{ "source": 2, "target": 1, "cost": 14 },
{ "source": 1, "target": 3, "cost": 32 },
{ "source": 3, "target": 1, "cost": 32 },
{ "source": 1, "target": 4, "cost": 41 },
{ "source": 4, "target": 1, "cost": 41 },
{ "source": 1, "target": 5, "cost": 52 },
{ "source": 5, "target": 1, "cost": 52 },
{ "source": 1, "target": 6, "cost": 58 },
{ "source": 6, "target": 1, "cost": 58 },
{ "source": 1, "target": 7, "cost": 20 },
{ "source": 7, "target": 1, "cost": 20 },
{ "source": 1, "target": 8, "cost": 1 },
{ "source": 8, "target": 1, "cost": 1 },
{ "source": 1, "target": 9, "cost": 54 },
{ "source": 9, "target": 1, "cost": 54 },
{ "source": 1, "target": 10, "cost": 75 },
{ "source": 10, "target": 1, "cost": 75 },
{ "source": 1, "target": 11, "cost": 15 },
{ "source": 11, "target": 1, "cost": 15 },
{ "source": 1, "target": 12, "cost": 45 },
{ "source": 12, "target": 1, "cost": 45 },
{ "source": 1, "target": 13, "cost": 94 },
{ "source": 13, "target": 1, "cost": 94 },
{ "source": 1, "target": 14, "cost": 41 },
{ "source": 14, "target": 1, "cost": 41 },
{ "source": 2, "target": 3, "cost": 82 },
{ "source": 3, "target": 2, "cost": 82 },
{ "source": 2, "target": 4, "cost": 44 },
{ "source": 4, "target": 2, "cost": 44 },
{ "source": 2, "target": 5, "cost": 83 },
{ "source": 5, "target": 2, "cost": 83 },
{ "source": 2, "target": 6, "cost": 91 },
{ "source": 6, "target": 2, "cost": 91 },
{ "source": 2, "target": 7, "cost": 78 },
{ "source": 7, "target": 2, "cost": 78 },
{ "source": 2, "target": 8, "cost": 51 },
{ "source": 8, "target": 2, "cost": 51 },
{ "source": 2, "target": 9, "cost": 6 },
{ "source": 9, "target": 2, "cost": 6 },
{ "source": 2, "target": 10, "cost": 81 },
{ "source": 10, "target": 2, "cost": 81 },
{ "source": 2, "target": 11, "cost": 77 },
{ "source": 11, "target": 2, "cost": 77 },
{ "source": 2, "target": 12, "cost": 93 },
{ "source": 12, "target": 2, "cost": 93 },
{ "source": 2, "target": 13, "cost": 97 },
{ "source": 13, "target": 2, "cost": 97 },
{ "source": 2, "target": 14, "cost": 33 },
{ "source": 14, "target": 2, "cost": 33 },
{ "source": 3, "target": 4, "cost": 66 },
{ "source": 4, "target": 3, "cost": 66 },
{ "source": 3, "target": 5, "cost": 47 },
{ "source": 5, "target": 3, "cost": 47 },
{ "source": 3, "target": 6, "cost": 54 },
{ "source": 6, "target": 3, "cost": 54 },
{ "source": 3, "target": 7, "cost": 39 },
{ "source": 7, "target": 3, "cost": 39 },
{ "source": 3, "target": 8, "cost": 98 },
{ "source": 8, "target": 3, "cost": 98 },
{ "source": 3, "target": 9, "cost": 90 },
{ "source": 9, "target": 3, "cost": 90 },
{ "source": 3, "target": 10, "cost": 5 },
{ "source": 10, "target": 3, "cost": 5 },
{ "source": 3, "target": 11, "cost": 27 },
{ "source": 11, "target": 3, "cost": 27 },
{ "source": 3, "target": 12, "cost": 61 },
{ "source": 12, "target": 3, "cost": 61 },
{ "source": 3, "target": 13, "cost": 95 },
{ "source": 13, "target": 3, "cost": 95 },
{ "source": 3, "target": 14, "cost": 19 },
{ "source": 14, "target": 3, "cost": 19 },
{ "source": 4, "target": 5, "cost": 34 },
{ "source": 5, "target": 4, "cost": 34 },
{ "source": 4, "target": 6, "cost": 10 },
{ "source": 6, "target": 4, "cost": 10 },
{ "source": 4, "target": 7, "cost": 20 },
{ "source": 7, "target": 4, "cost": 20 },
{ "source": 4, "target": 8, "cost": 44 },
{ "source": 8, "target": 4, "cost": 44 },
{ "source": 4, "target": 9, "cost": 33 },
{ "source": 9, "target": 4, "cost": 33 },
{ "source": 4, "target": 10, "cost": 29 },
{ "source": 10, "target": 4, "cost": 29 },
{ "source": 4, "target": 11, "cost": 36 },
{ "source": 11, "target": 4, "cost": 36 },
{ "source": 4, "target": 12, "cost": 62 },
{ "source": 12, "target": 4, "cost": 62 },
{ "source": 4, "target": 13, "cost": 77 },
{ "source": 13, "target": 4, "cost": 77 },
{ "source": 4, "target": 14, "cost": 63 },
{ "source": 14, "target": 4, "cost": 63 },
{ "source": 5, "target": 6, "cost": 73 },
{ "source": 6, "target": 5, "cost": 73 },
{ "source": 5, "target": 7, "cost": 6 },
{ "source": 7, "target": 5, "cost": 6 },
{ "source": 5, "target": 8, "cost": 91 },
{ "source": 8, "target": 5, "cost": 91 },
{ "source": 5, "target": 9, "cost": 5 },
{ "source": 9, "target": 5, "cost": 5 },
{ "source": 5, "target": 10, "cost": 61 },
{ "source": 10, "target": 5, "cost": 61 },
{ "source": 5, "target": 11, "cost": 11 },
{ "source": 11, "target": 5, "cost": 11 },
{ "source": 5, "target": 12, "cost": 91 },
{ "source": 12, "target": 5, "cost": 91 },
{ "source": 5, "target": 13, "cost": 7 },
{ "source": 13, "target": 5, "cost": 7 },
{ "source": 5, "target": 14, "cost": 88 },
{ "source": 14, "target": 5, "cost": 88 },
{ "source": 6, "target": 7, "cost": 52 },
{ "source": 7, "target": 6, "cost": 52 },
{ "source": 6, "target": 8, "cost": 86 },
{ "source": 8, "target": 6, "cost": 86 },
{ "source": 6, "target": 9, "cost": 48 },
{ "source": 9, "target": 6, "cost": 48 },
{ "source": 6, "target": 10, "cost": 13 },
{ "source": 10, "target": 6, "cost": 13 },
{ "source": 6, "target": 11, "cost": 31 },
{ "source": 11, "target": 6, "cost": 31 },
{ "source": 6, "target": 12, "cost": 91 },
{ "source": 12, "target": 6, "cost": 91 },
{ "source": 6, "target": 13, "cost": 62 },
{ "source": 13, "target": 6, "cost": 62 },
{ "source": 6, "target": 14, "cost": 30 },
{ "source": 14, "target": 6, "cost": 30 },
{ "source": 7, "target": 8, "cost": 79 },
{ "source": 8, "target": 7, "cost": 79 },
{ "source": 7, "target": 9, "cost": 94 },
{ "source": 9, "target": 7, "cost": 94 },
{ "source": 7, "target": 10, "cost": 58 },
{ "source": 10, "target": 7, "cost": 58 },
{ "source": 7, "target": 11, "cost": 12 },
{ "source": 11, "target": 7, "cost": 12 },
{ "source": 7, "target": 12, "cost": 81 },
{ "source": 12, "target": 7, "cost": 81 },
{ "source": 7, "target": 13, "cost": 2 },
{ "source": 13, "target": 7, "cost": 2 },
{ "source": 7, "target": 14, "cost": 89 },
{ "source": 14, "target": 7, "cost": 89 },
{ "source": 8, "target": 9, "cost": 15 },
{ "source": 9, "target": 8, "cost": 15 },
{ "source": 8, "target": 10, "cost": 94 },
{ "source": 10, "target": 8, "cost": 94 },
{ "source": 8, "target": 11, "cost": 23 },
{ "source": 11, "target": 8, "cost": 23 },
{ "source": 8, "target": 12, "cost": 50 },
{ "source": 12, "target": 8, "cost": 50 },
{ "source": 8, "target": 13, "cost": 79 },
{ "source": 13, "target": 8, "cost": 79 },
{ "source": 8, "target": 14, "cost": 65 },
{ "source": 14, "target": 8, "cost": 65 },
{ "source": 9, "target": 10, "cost": 68 },
{ "source": 10, "target": 9, "cost": 68 },
{ "source": 9, "target": 11, "cost": 81 },
{ "source": 11, "target": 9, "cost": 81 },
{ "source": 9, "target": 12, "cost": 34 },
{ "source": 12, "target": 9, "cost": 34 },
{ "source": 9, "target": 13, "cost": 21 },
{ "source": 13, "target": 9, "cost": 21 },
{ "source": 9, "target": 14, "cost": 16 },
{ "source": 14, "target": 9, "cost": 16 },
{ "source": 10, "target": 11, "cost": 10 },
{ "source": 11, "target": 10, "cost": 10 },
{ "source": 10, "target": 12, "cost": 12 },
{ "source": 12, "target": 10, "cost": 12 },
{ "source": 10, "target": 13, "cost": 60 },
{ "source": 13, "target": 10, "cost": 60 },
{ "source": 10, "target": 14, "cost": 61 },
{ "source": 14, "target": 10, "cost": 61 },
{ "source": 11, "target": 12, "cost": 36 },
{ "source": 12, "target": 11, "cost": 36 },
{ "source": 11, "target": 13, "cost": 78 },
{ "source": 13, "target": 11, "cost": 78 },
{ "source": 11, "target": 14, "cost": 79 },
{ "source": 14, "target": 11, "cost": 79 },
{ "source": 12, "target": 13, "cost": 54 },
{ "source": 13, "target": 12, "cost": 54 },
{ "source": 12, "target": 14, "cost": 33 },
{ "source": 14, "target": 12, "cost": 33 },
{ "source": 13, "target": 14, "cost": 29 },
{ "source": 14, "target": 13, "cost": 29 }
]
}
}