Since R was invented in 1993, it has become a widely used programming language for statistical analysis. From academia to the tech world and beyond, R is used for a wide range of statistical analysis.
R's ubiquity in the world of statistics leads many to assume that it is only useful to those who do complex statistical work. But as R has grown in popularity, the number of ways it can be used has grown as well. Today, R is used for:
- Data visualization
- Map making
- Sharing results through reports, slides, and websites
- Automating processes
- And much more!
The idea that R is only for statistical analysis is outdated and inaccurate. But, without a single book that demonstrates the power of R for non-statistical purposes, this perception persists.
Enter R Without Statistics.
R Without Statistics will show ways that R can be used beyond complex statistical analysis. Readers will learn about a range of uses for R, many of which they have likely never even considered.
Each chapter will, using a consistent format, cover one novel way of using R.
- Readers will first be introduced to an R user who has done something novel and learn how using R in this way transformed their work.
- Following this, there will be code samples that demonstrate exactly how the R user did the thing they are being profiled for.
- Finally, there will be a summary, with lessons learned from this novel way of using R.
Below is an outline of the R Without Statistics. While I have not yet confirmed with all of the subjects about their willingness to be interviewed, I have relationships with most of them and am confident they would accept my offer.
R Without Statistics will have an introduction, followed by three sections (illuminate, communicate, automate), and a conclusion.
Through an interview with data visualization practitioner Chris Knox, the introduction will start with the story of how the government of New Zealand used R in order to develop its remarkably successful COVID-19 policies.
This section will focus on ways to illuminate results making data visualization, maps, and tables with R.
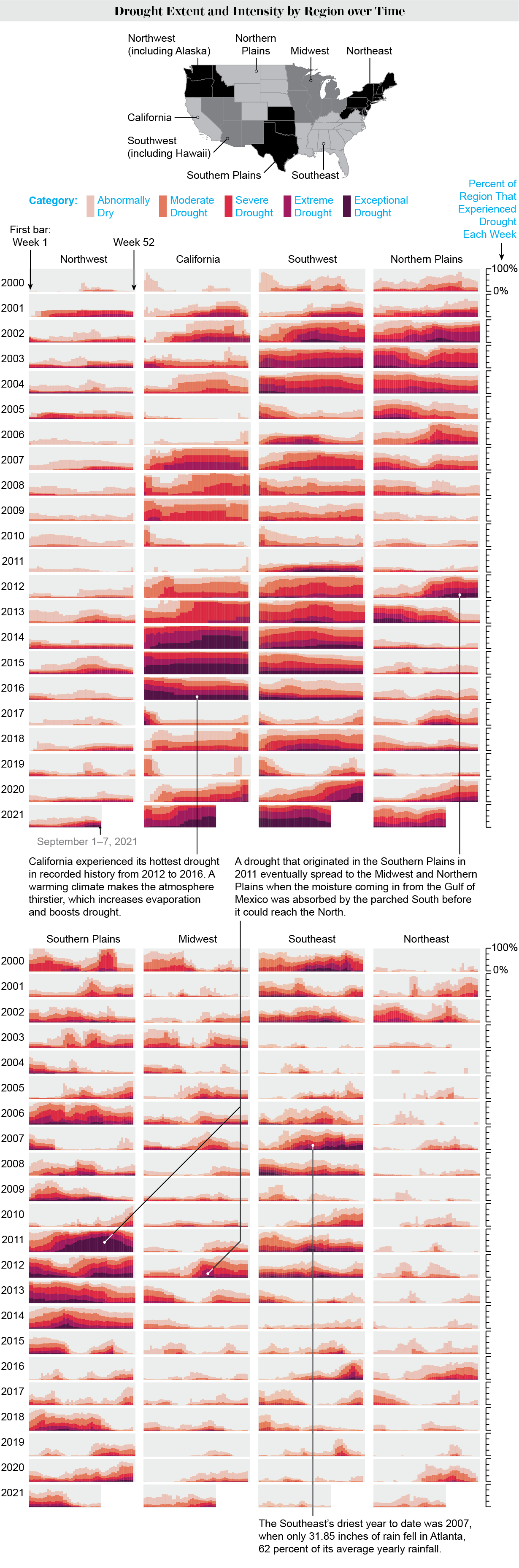
Chapter 1 will talk about applying general principles of high-quality static data viz when working with ggplot. Through an interview with Cédric Scherer and Georgios Karamanis focusing on their piece in Scientific America about climate change driving drought, we’ll pull out general principles of data visualization and how to apply them in R.
Chapter 2 will discuss the benefits of making a custom ggplot theme. I’m hoping to connect with the developers of the bbplot package (if I'm unsuccessful in connecting with them, I have alternatives in mind). This package is used by the BBC to ensure their figures all follow organizational style requirements. We’ll discuss ways that having a custom theme can improve the data viz that organizations produce.

Chapter 3 will focus on making maps with R. In recent years, R has become a full-fledged GIS tool, as powerful as any other GIS product on the market. I'll interview Abdoul Madjid about his maps of the evolution of COVID-19 in the United States throughout 2021.

Chapter 4 will explore ways to make high-quality tables. Tables are often used, but their design is too often ignored. This chapter will consist of an interview with Tom Mock, who has done a series of blog posts on making high-quality tables. I'll focus in particular on his post 10+ Guidelines for Better Tables in R. This post takes an article by Jon Schwabish on table design principles and shows how to implement them in R.
Moving beyond individual design elements, the second section of the book will focus on ways to communicate results.
Many people start using R as a direct replacement for other tools. But R can do more than simply run analyses that you might do in Excel, SPSS, or some other tool.
One of R's unique differentiators is R Markdown. R Markdown allows you to combine code and text. While this may not sound impressive, this combination allows you to automate reporting. Instead of having to, say, run analyses in SPSS, generate charts in Excel, and then write reports in Word, we can do all of our work in R — and rerun our code at any point to regenerate reports.
In this chapter, I'll interview Alison Hill. Alison has written and spoken extensively about the range of things you can do with R Markdown. We'll discuss the benefits of R Markdown and some of the unique ways you can use it.
R Markdown is useful if you're producing a single report. It's especially useful when you're producing multiple reports. The process of parameterized reporting allows you to do this. In this chapter, I'll interview Aaron Williams, data scientist at the Urban Institute, about how the prominent organization uses parameterized to create state-level reports.
The beauty of R Markdown is that you can create one document and then export it to multiple formats. One format is presentations. In this chapter, I'll interview Silvia Canelón about how to make slides using the xaringan package. Building on Silvia's 2020 talk Sharing Your Work with xaringan, the interview will discuss how to make slides in R and how you can, with a few small tweaks, make a set of slides that follow your organization's branding guidelines.
When the COVID-19 pandemic hit, many R users created tools to monitor its spread. One of these was Matt Herman. Based just north of New York City, he developed a COVID-19 dashboard for Westchester County.
This dashboard, made with the distill, plotly, leaflet, and DT packages, shows the power of reporting online. While R can create high-quality static reports, it can also be used to make reports that live online. Doing so takes advantage of interactive capabilities that only online reporting offers. It also makes it possible to automatically update data in real time, something the Westchester County dashboard does and which I will discuss with Matt.
The book Automate the Boring Stuff with Python has sold over 285,000 copies. It's so popular because it teaches people to avoid tedious tasks through programming. R can do the same — and it's one of the most compelling reasons to learn to use it.
This section of the book will show examples of ways that you can automate tasks using R. It will provide some specific examples using automated programming interfaces (aka APIs): automating Census data collection and pulling in survey data as it comes in. And it will also discuss some general automation techniques: developing your own functions and collecting these functions in a custom package.
My work often involves analyzing Census data. Before I switched to R, I would access data by going to the Census Bureau website, downloading data files, and then analyzing them in Excel. Every time I needed a new bit of data, I had to repeat this process.
With R, it's different: the tidycensus package makes it possible to access Census data directly from R. This makes it possible to do things that would have previously taken me a long time. Writing code to access data means I can change just a few lines and get new data.
In this chapter, I'll interview Kyle Walker, one of the developers of the tidycensus package. I'll ask him about the background for its development and how it is used today.
If you do survey research, it is often a chore to work with the data that comes from them. You often have to download the data from your survey platform before working with it in Excel, SPSS, etc. Doing this once isn't the end of the world, but, as usually happens, you often have to repeat the process when new surveys come in. R helps us avoid this issue.
There are packages that allow R users to connect directly to data collected by surveys. One of these is the qualtRics package. This package allows you to connect directly to the Qualtrics survey platform, pulling in new data each time you run the code. I'll interview package maintainer Julia Silge to discuss the benefits of using the qualtRics package to automate the process of accessing survey data.
This chapter will be slightly different from the others. Rather than focus on the work of one R user, it will be a round-up of the work of many R users.
For this chapter, I'll interview multiple people about some of the most powerful functions they've created. These include functions that do things like:
- Automatically pulling in and formatting race/ethnicity data from the American Community Survey (a function I have created for my own work)
- Automating the process of cleaning messy data from Survey Monkey
- Calculating the percent of grouped observations
- Automatically viewing snippets of data in Excel
Each interview will discuss the problem that led to the function's creation and a demonstration of how to use it.
For many R users, making their own functions is the first step to automating their work. Having these functions is great to avoid copying and pasting code. But what happens when you need to use a function in multiple projects? Unfortunately, for many people, this means a return to copying and pasting, taking code used to make functions from one project to another. As with all copying and pasting of code, this is both inefficient and has the potential to lead to errors.
What is a better solution? Bundling functions into a custom package. This allows you to have access to functions across projects, allowing you to create code once and use it multiple times.
Garrick Aden-Buie and Travis Gerke did just this when they worked at the Moffett Cancer Center. I'll interview them about the set of internal packages they made, discussing how doing so improved the work of the organization.
When people evaluate tools, they often focus on their functionality: what types of analyses can they do with them, how hard they are to learn, etc. Missing from this evaluation is a key part of what makes R special: its uniquely supportive community.
In the conclusion to the book, I'll discuss why the R community is not just a nice add-on. Learning new tools always has challenges. Being able to find people to provide help is as key to new users successfully learning a new tool as are any of its functionalities. R is worth learning not only because it is a powerful tool, but also because, whenever you run into problems, there is a community ready, willing, and able to support you.
This book has two main audiences:
-
Active R users who can learn new ways to use R. In running R for the Rest of Us, I've constantly been struck by how often people I see using R in quite complex ways are not familiar with some of the "simpler" uses for R that R Without Statistics will cover. Displaying what's possible and offering clear guidance on how to implement these uses will serve these users.
-
Users of other tools considering switching to R. Most books on R (rightly) assume the reader is already using this tool. But there is a whole group of potential users of Excel, SPSS, SAS, Stata, and other tools who are considering switching to R. Having a book that explains not just how to use R, but also why R is worth learning is valuable for this audience.
Because this book is a novel approach to talking about R, there is no direct competitor. However, there is a model for this type of book — and it shows its potential.
Automate the Boring Stuff with Python has sold over 285,000 copies. R Without Statistics will take a similar approach, focusing on "simpler" uses that show the power of R for a wide variety of users.
There are some competitive books on specific topics covered in R Without Statistics, listed below.
- Kieran Healy's Data Visualization: A Practical Introduction
- Claus Wilke's Fundamentals of Data Visualization
- The upcoming third edition of ggplot2: Elegant Graphics for Data Analysis by Hadley Wickham, Danielle Navarro, and Thomas Lin Pedersen
- Cédric Scherer's upcoming book on ggplot
- Geocomputation with R by Robin Lovelace, Jakub Nowosad, and Jannes Muenchow
- R Markdown: The Definitive Guide by Yihui Xie, J. J. Allaire, and Garrett Grolemund
- R Markdown Cookbook by Yihui Xie, Christophe Dervieux, Emily Riederer
- Analyzing US Census Data: Methods, Maps, and Models in R by Kyle Walker
- R for Data Science by Hadley Wickham and Garrett Grollemund
- Advanced R by Hadley Wickham
- R Packages by Hadley Wickham and Jenny Bryan
The market for this book is extremely large.
While the Tiobe rankings of language popularity have their critics, the fact that R is in 12th place give an indication of its broad popularity. With millions of users around the world, R is extremely widely used.
There are also millions of potential R users this book can serve. Users of Excel, SPSS, SAS, Stata, and other tools for working with data can find value in learning what R is capable of.
David Keyes is founder and CEO of R for the Rest of Us. Since starting R for the Rest of Us in 2019, David has helped thousands of users who don't think of themselves as programmers learn to use R. David is uniquely skilled in explaining complex technical concepts in simple ways.
David's skill at communicating complex technical concepts comes from his extensive writing experience. In addition to dozens of articles on the R for the Rest of Us blog, David has:
-
Written a Washington Post op-ed on inequality in the education system
-
Founded and written articles for XI Quarterly, a magazine about soccer in North America
-
Completed a 200+ page dissertation on immigration and youth sports
David also has extensive marketing experience that will serve this book well. Having founded R for the Rest of Us from scratch, David has become one of the leading figures in the R community. With over 12,000 Twitter followers (plus over 5,000 on his personal account), an email list of close to 3,000 subscribers, and personal connections with nearly all of the most prominent figures in the R community, David has the tools to create and market a highly successful book.