Home
SPL(Structured Process Language)A programming language specially for structured data computing
- Beyond the computing power of the database
- Open computing system
- Agile syntax
- Structured data is everywhere.
- Structured data computing has always been the mainstream of data processing.
There are three main types of programming languages for processing structured data at present:
- SQL the mainstream programming language of relational database
- Java/C#/C++ more basic high-level language
- Python emerging data processing and artificial intelligence language
Data processing and computing are everywhere, but there is no good technology to solve these problems. There are many SPL application scenarios, and they are mainly in the following six aspects:
- Got SQL
- Beyond SQL
- Cooperate DB
- Surpass DB
- For Excel
- For Industry
SQL has certain computing power, but it is not available in many scenarios, so you will have to hard code in Java. SPL provides lightweight computing power independent of database and can process data in any scenario:
- Structured text (txt/csv) calculation
- Excel calculation
- Perform SQL on files
- Multi-layer json calculation
- Multi-layer xml calculation
- Java computing class library, surpass Stream/Kotlin/Scala
- Replace ORM to implement business logic
- SQL-like calculation on Mongodb, association calculation
- Post calculation of WebService/Restful
- Post calculation of Salesforce, Post calculation of SAP
- Post calculation of various data sources: HBase,Cassandra,Redis,ElasticSearch,Kafka,…
Calculation on files
You can calculate files through SPL native syntax, and support SQL file query, which is simple and convenient.
- Two file calculation methods are provided
- If familiar with SQL, you can start at zero cost
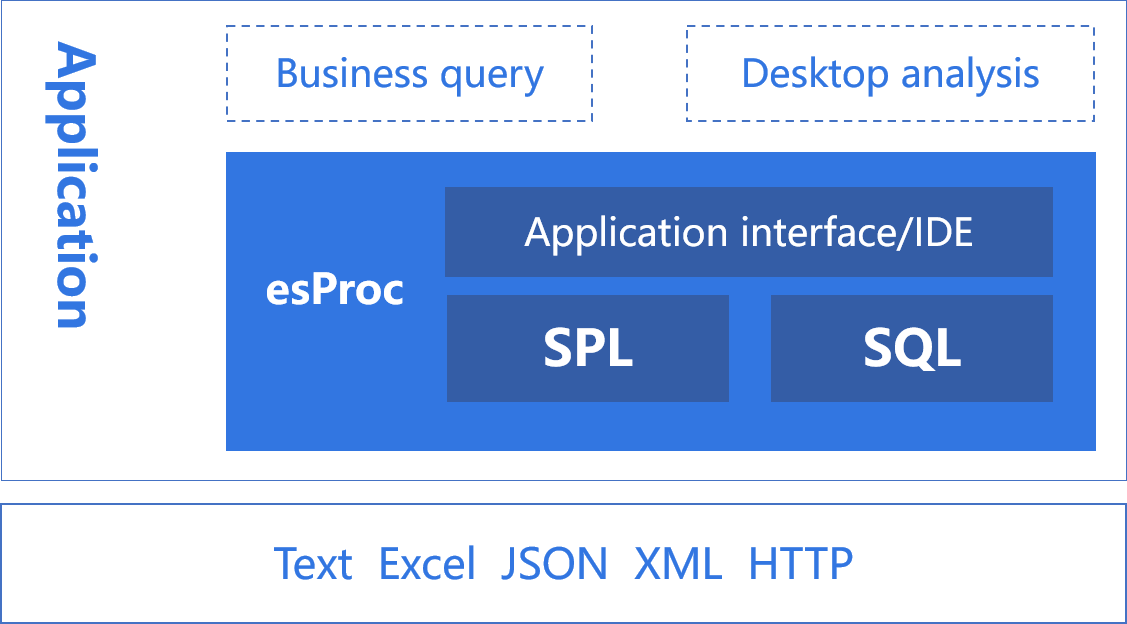
MongoDB calculation
SPL can enhance mongoDB's computing power and simplify the computing process.
- Make mongoDB equal to or stronger than the computing power of RDB
- After enhancing the computing power, give full play to the original advantages of mongoDB
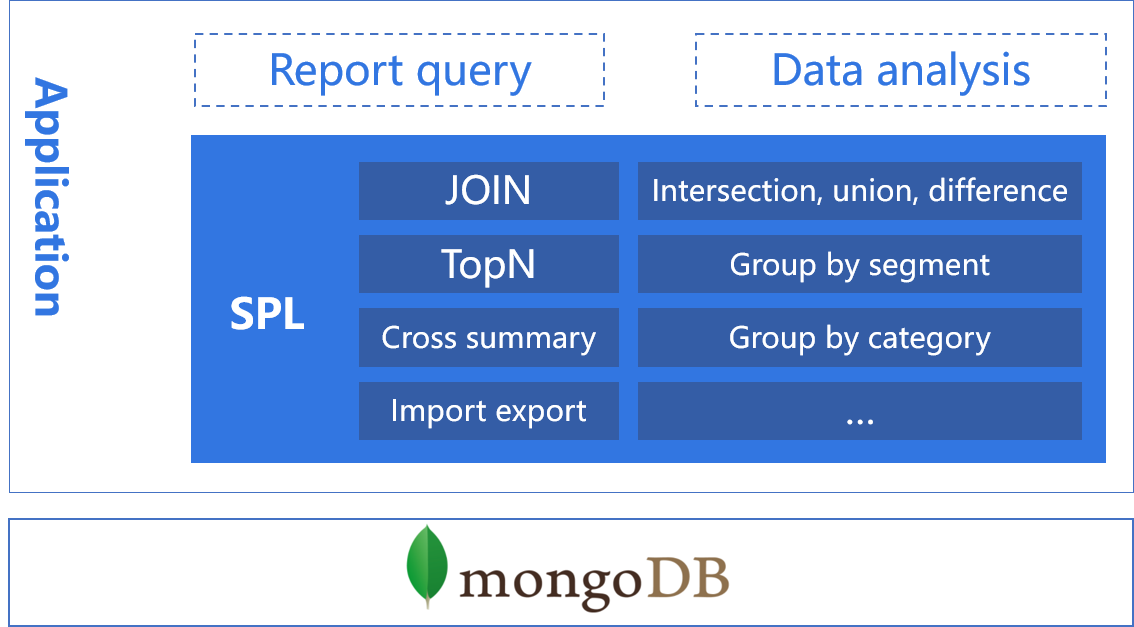
Diverse data source calculation
SPL provides the computing power independent of the database to complete the post calculation of various data sources.

SQL is difficult to deal with complex sets and ordered operations, and it is often read out and calculated in Java. SPL has complete set capability, especially supports ordered and step-by-step calculation, which can simplify these operations:
- Ordered set
- Position reference
- Grouping subsets
- Non-equivalence grouping
- Multi-level association operation
- Static and dynamic pivot
- Recursion and iteration
- Step-by-step and loop operation
- Text and date time operation
- …
SQL vs SPL
Set-orientation
SQL is incompletely set-oriented
- Cannot describe a set of sets
- Field value can no longer be a set
SPL provides richer
- Set operation Library
- Support lambda syntax
- Support dynamic data structure
Support lambda syntax
SQL lacks discreteness
- No natural sequence number, it is troublesome to refer to the specified set member
- Only have a table with single record, do not have separate record
SPL provides richer
- Set members can exist outside the set
- Convenient for separate reference
Completely set-oriented
SPL set-orientation supported by discreteness
Complete set-orientation requires the support of discreteness
- Allow separate members to form a new set
- Ordered calculation is a combination of set-orientation and discreteness
The computing power of the database is closed and cannot process data outside the database. It is often necessary to perform ETL to import data into the same database before processing. SPL provides open and simple computing power, which can directly read multiple databases, realize mixed data calculation, and assist the database to do better calculation.
- Fetch data in parallel to accelerate JDBC
- SQL migration among different types of databases
- Cross database operations
- T+0 statistics and query
- Replace stored procedure operation, improve code portability and reduce coupling
- Avoid making ETL into ELT or even LET
- Mixed calculation of multiple data sources
- Reduce intermediate tables in the database
- Report data source development, support hot switching, multiple data sources and improve development efficiency
- Implement microservices, occupy less resources and support hot switching
- …
Assist RDB
SPL assists RDB calculation and improves RDB capability.
- SQL migration transforms standard SQL into various database "dialects“
- Fetching data in parallel improves performance
- Cross database / heterogeneous database calculation further enhances RDB capabilities

Replace stored procedure
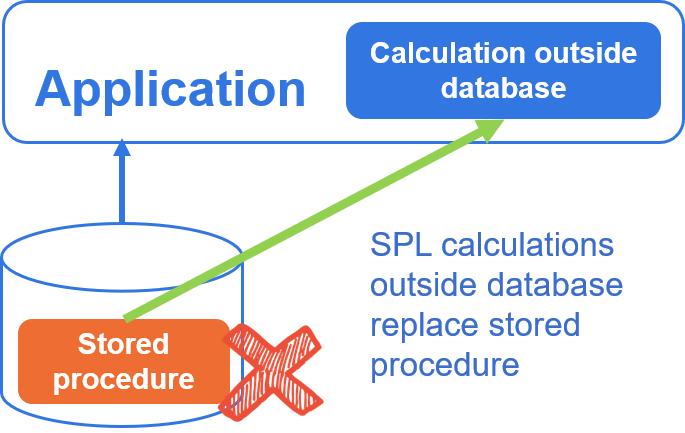
- Data preparation
- Presentation preparation
Problems of stored procedure
- Cause intra application and inter application coupling
- Low safety
- Poor portability
Database decoupling
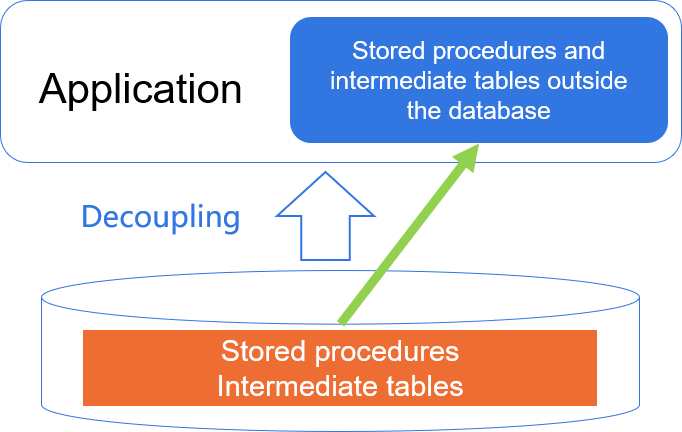
- Put stored procedures and intermediate tables in the application
- The database only undertakes storage and a small amount of (general) calculation -Application and database are decoupled, easy to maintain and expand
Cross database cluster
Multi database cluster computing is realized with the cross database and parallel ability of SPL.
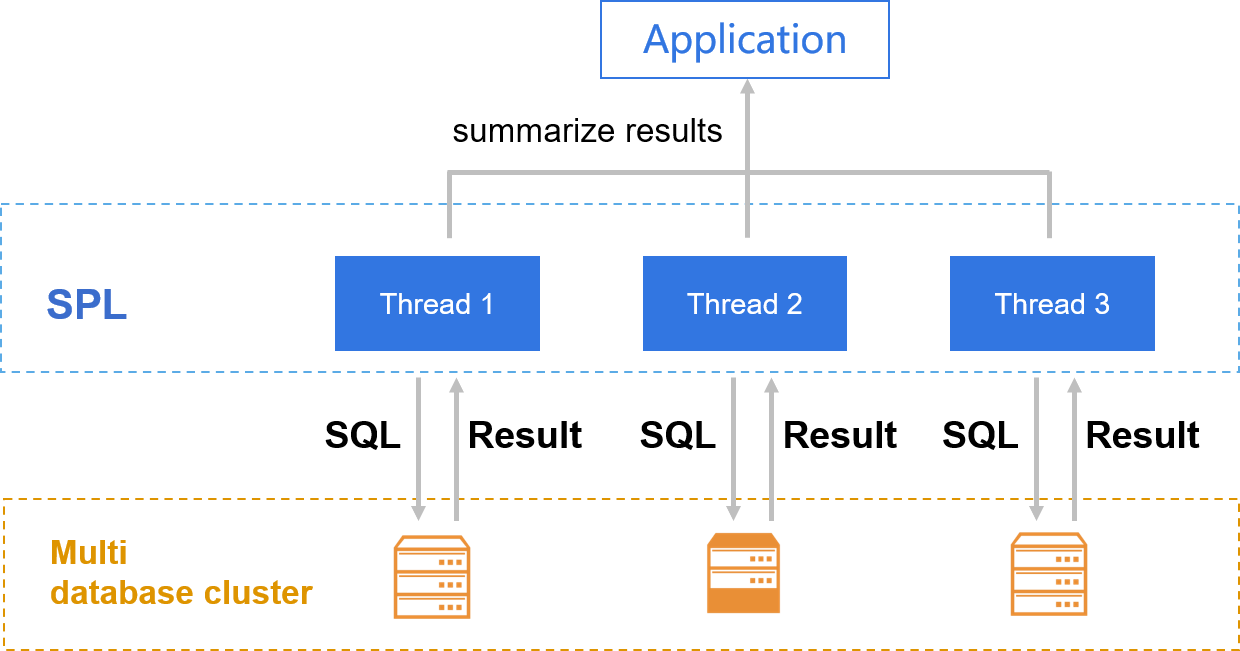
T+0 query
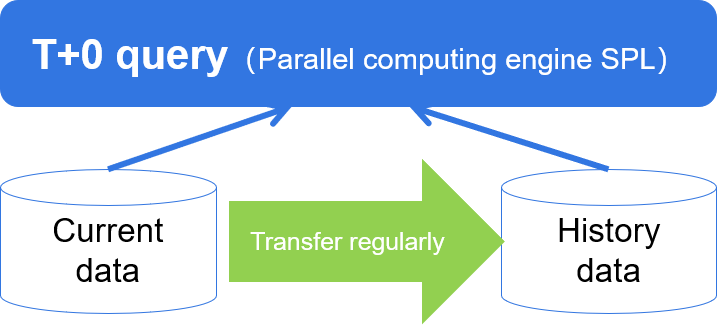
- Transaction consistency requirements
- If history data and current data are in the same database, the amount of data is too huge
- If history data and current data are in different databases, cross database calculation is difficult
Parallel cross-database computing to implement T+0
- Historical data can also be saved as files
ETL
Traditional ETL often starts with L and then ET, which is time-consuming and laborious; The real ETL process can be realized through SPL.
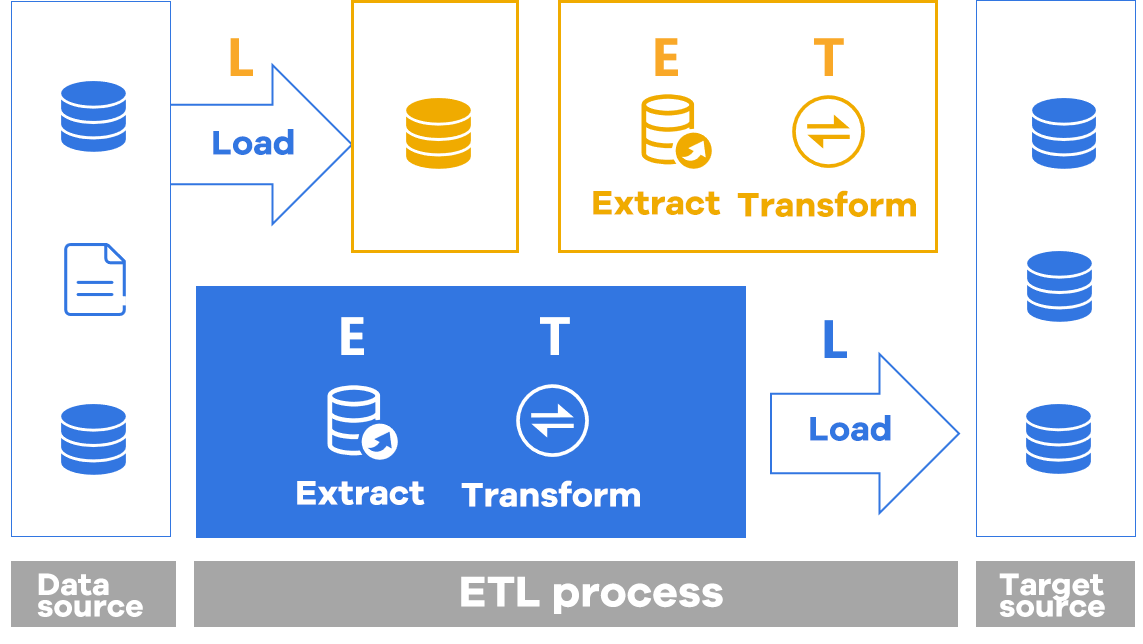
ETL complex calculation
- Processing outside the database to reduce the burden on the database
- Reduce IO and shorten time window
- Simple and flexible implementation
- Allow multi-source mixed processing
Assist Microservice
The data processing of microservices often depends on Java hard coding, and it is difficult to implement complex computing. The combination of SPL and microservice framework to implement data processing is more concise and efficient than other development languages.
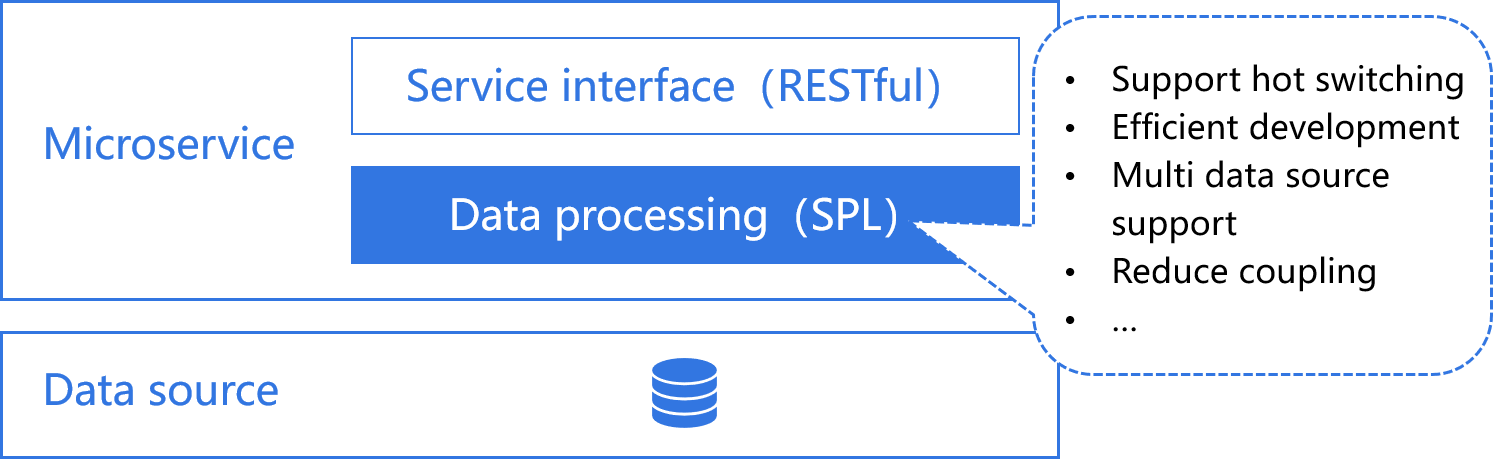
SQL is difficult to implement high-performance algorithms. The performance of big data operations can only rely on the optimization engine of the database, but it is often unreliable in complex situations.
SPL provides a large number of basic high-performance algorithms (many of which are pioneered in the industry) and efficient storage formats. Under the same hardware environment, it can obtain much better computing performance than the database, and can comprehensively replace the big data platform and data warehouse.
- In-memory search: binary search, sequence number positioning, position index, hash index, multi-layer sequence number positioning
- Dataset in external storage: parallel computing of text file, binary storage, double increment segmentation, columnar storage composite table, ordered storage and update
- Search in external storage: binary search, hash index, sorting index, row-based storage and valued index, index preloading, batch search and set search, multi index merging, full-text searching
- Traversing technique: post filter of cursor, multi-purpose traversal, parallel traversing and multi cursors, aggregation extension, ordered traversing, program cursor, partially ordered grouping and sorting, sequence number grouping and controllable segmentation
- Association technique: foreign key addressing, foreign key serialization, index reuse, alignment sequence, large dimension table search, unilateral splitting, orderly merging, association positioning, schedule
- Multidimensional analysis: pre summary and time period pre summary, alignment sequence, tag bit dimension
- Distributed: free computing and data distribution, cluster multi-zone composite table, cluster dimension table, redundant fault tolerance, spare tire fault tolerance, Fork-Reduce, multi job load balancing
Decisive factors of computing performance
- Computing efficiency depends on both hardware and software.
- Software performance is algorithm efficiency.
- Algorithm efficiency is determined by algorithm design and algorithm implementation.
- It is futile to only think of a good algorithm but unable to implement it.
- The lack of high-performance programming language will limit the implementation of good algorithms.
Structured data is the focus
- At present, data calculation is still based on structured data generated by business system.
- The industry mainly relies on large memory and large cluster to improve the performance of structured data computing.
- The essence of large memory and large cluster is to improve the hardware capability vertically or horizontally.
- The software core still uses SQL based relational algebra system.
- SQL is too rough to implement many high-performance algorithms.
Why can't the database run fast?
- The reason why SQL is difficult to implement efficient algorithms is its theoretical system (relational algebra).
- The defects in theory are difficult to be made up by engineering.
SPL high performance algorithms and storage schemes
In-memory search
- Binary search
- Sequence number positioning
- Position index
- Hash index
- Multi-layer sequence number positioning
Dataset in external storage
- Segmentation of text files
- Bin file and double increment segmentation
- Data types
- Composite table and columnar storage
- Order and supplementary file
- Data update and multi-zone composite table
Search in external storage
- Binary search
- Hash index
- Sorting index
- Row-based storage and valued index
- Index preloading
- Batch search
- Set search
- Multi index merging
- ull-text searching
Traversing technique
- Post filter of cursor
- Multi-purpose
- Parallel traversing
- Parallel loading of database
- Multi cursors
- Group aggregation
- Understanding aggregation
- Redundant grouping key
Ordered traversing
- Ordered group aggregation
- Ordered grouping subsets
- Program cursor
- Partially ordered grouping
- Sequence number grouping and controllable segmentation
- Index sorting
Foreign key association
- Foreign key addressing
- Temporary addressing
- foreign key serialization
- Inner join syntax
- index reuse
- alignment sequence
- large dimension table search
- unilateral splitting
Merge and join
- Ordered merging
- Merge by segment
- Association positioning
- schedule
Multidimensional analysis
- Partial pre-summary
- Time period pre-summary
- Redundant sorting
- alignment sequence
- tag bit dimension
Cluster
- free computing and data distribution
- cluster multi-zone composite table
- cluster dimension table
- Dimension table segmentation
- redundant fault tolerance
- spare tire fault tolerance
- multi job load balancing
SPL performance
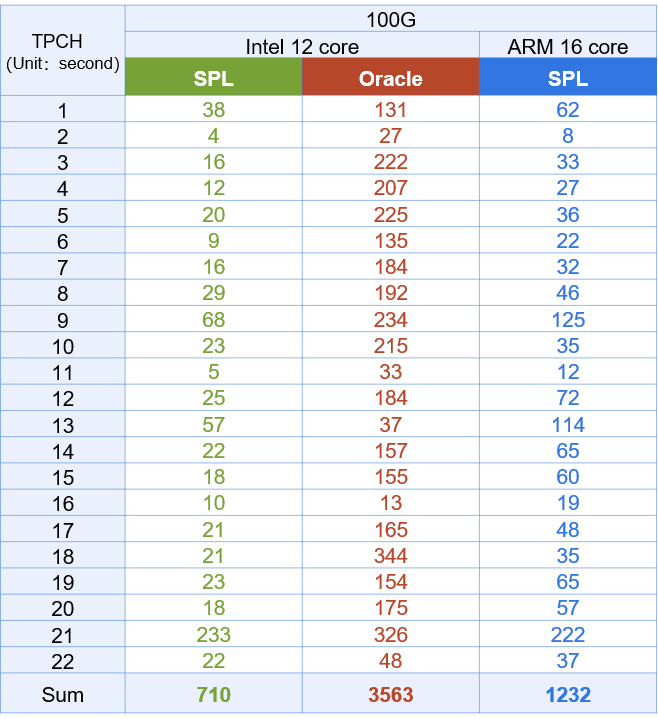
Hardware configuration:Intel3014 1.7G/12 core/64G memory , ARM/16 core/32G memory
In the same hardware environment, SPL performance is much better than Oracle; Even SPL using low-end chips can surpass Oracle with high-end chips.
【Application case】 Mobile Banking: optimization of large concurrent associated query of current details
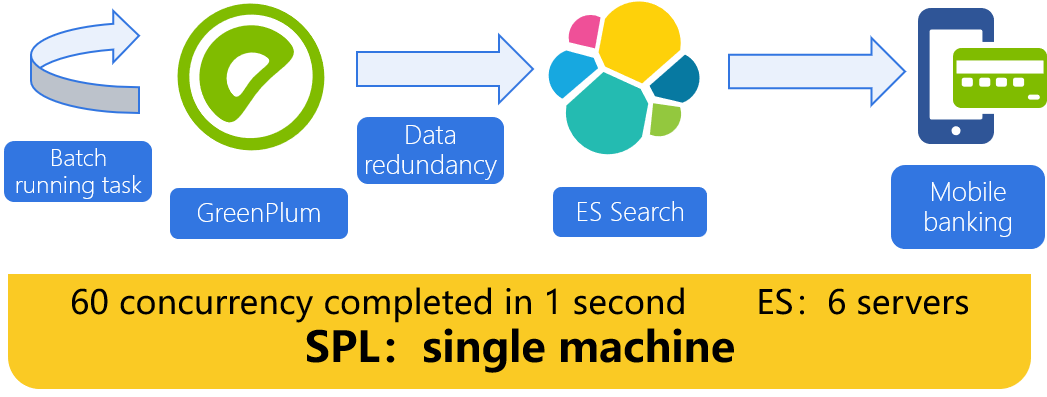
Concurrent access is huge
Mobile banking/ online banking, hundreds of thousands/ millions of concurrent details query
ES does not support association
The association between details and organization dimension tables cannot be realized, so wide table redundancy is required
Updating dimension tables takes a long time
For dimension table data adjustment, the wide table data should be fully updated
【Application case】 User portrait: intersection of customer groups, acceleration of real-time calculation
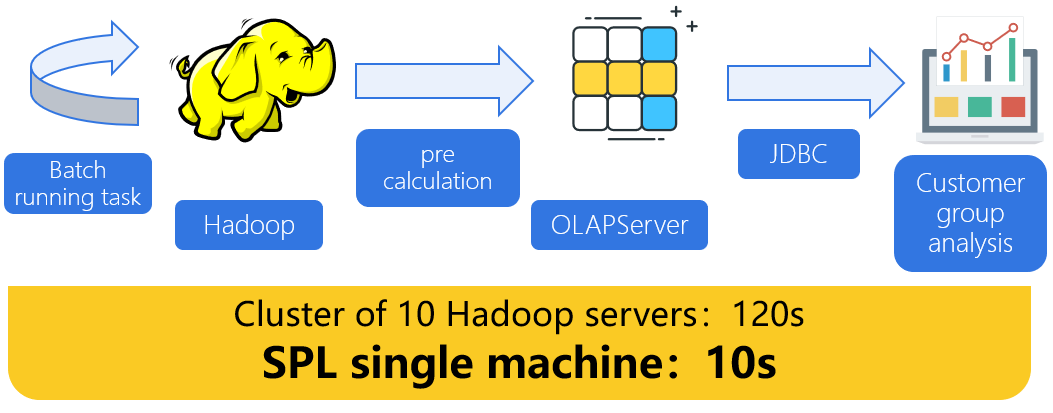
Huge amount of data
Hundreds of millions of customers have many to many relationships with thousands of customer groups, with dozens of dimensions
Unable to pre calculate
Thousands of customer groups, too many permutations and combinations
Real time computing is difficult
The database calculates the intersection in real time and filters the dimensions, and cannot respond in seconds.
Three ways of analyzing and processing Excel:
BI Tool
- Only regular calculation can be implemented
- Unable to complete data preparation
Data Tool
- Only modelized calculations can be processed
- Unable to complete flexible and complex calculations
Programming
- Can handle all situations
【Conclusion】 Programming is the most effective way to deal with structured data.But programming languages such as Python are not easy to use.
SPL provides Excel-oriented set operations
Cell value and summary value calculation
- Calculate using adjacent rows and intervals
- Accumulation that may terminates early
- Use adjacent rows to calculate when the same type of data is continuous
- Use adjacent rows to calculate when the same type of data is discontinuous
- Use the summary information of the same type of data
- ……
Set operation and subordinate judgment
- Intersection, union and difference of simple members
- Intersection, union and difference of row-style data
- Intersection, union and difference of uncertain number of sets
- Set equality and subordinate judgment
- Order-unrelated set equality and subordinate judgment
- ……
Duplication judgment, count and deduplication
- Judge whether there is duplicate data
- Count the number of repetitions
- Count the number of repetitions of uncertain number of columns
- Deduplication of row-style data
- Deduplication of simple data
- ……
Sorting and ranking
- Align in the specified order
- Align in the specified order with duplicate values
- Concatenate members with the same ranking
- Sort within the same category
- Ranking under category
- ……
Special grouping and aggregate methods
- Group every N members
- Use adjacent data as grouping condition
- Group when empty or non empty row is encountered
- Group by interval of data values
- Concatenate the data in the category into text
- ……
Association and comparison
- Associated table reference
- Interval association
- Two-dimension association table
- Use interval range to query association table
- Associate multiple rows of data
- ……
Row-column transpose
- Row to column of fixed column
- Interchange between row-style table and crosstab
- Row/column conversion of high level categories
- Concatenate data in a category into a column horizontally
- When data in a category is concatenated into a column, it needs to be classified or sorted again
- ……
Expansion and supplement
- Generate continuous interval
- Expand one row to multiple rows based on values
- Split text and expand to multiple rows
- Fill in the missing part in the continuous values
- Fill in several empty rows every N rows
- ……
There are a large number of time series data in industrial scenarios, and databases often only provide SQL. The ordered calculation capability of SQL is very weak, resulting in that it can only be used for data retrieval and cannot assist in calculation.
Many basic mathematical operations are often involved in industrial scenarios. SQL lacks these functions and the data can only be read out to process.
SPL can well support ordered calculation, and provides rich mathematical functions, such as matrix and fitting, and can more conveniently meet the calculation requirements of industrial scenes.
- Time series cursor: aggregation by granularity, translation, adjacence reference, association and merging
- Historical data compression and solidification, transparent reference
- Vector and matrix operations
- Various linear fitting: least squares, partial least squares, Lasso, ridge …
- …
Industrial algorithms often need repeated experiments. SPL development efficiency is very high, and you can try more within the same time period:
- Instrument anomaly discovery algorithm
- Abnormal measurement sample locating
- Curve lifting and oscillation pattern recognition
- Constrained linear fitting
- Pipeline transmission scheduling algorithm
- …
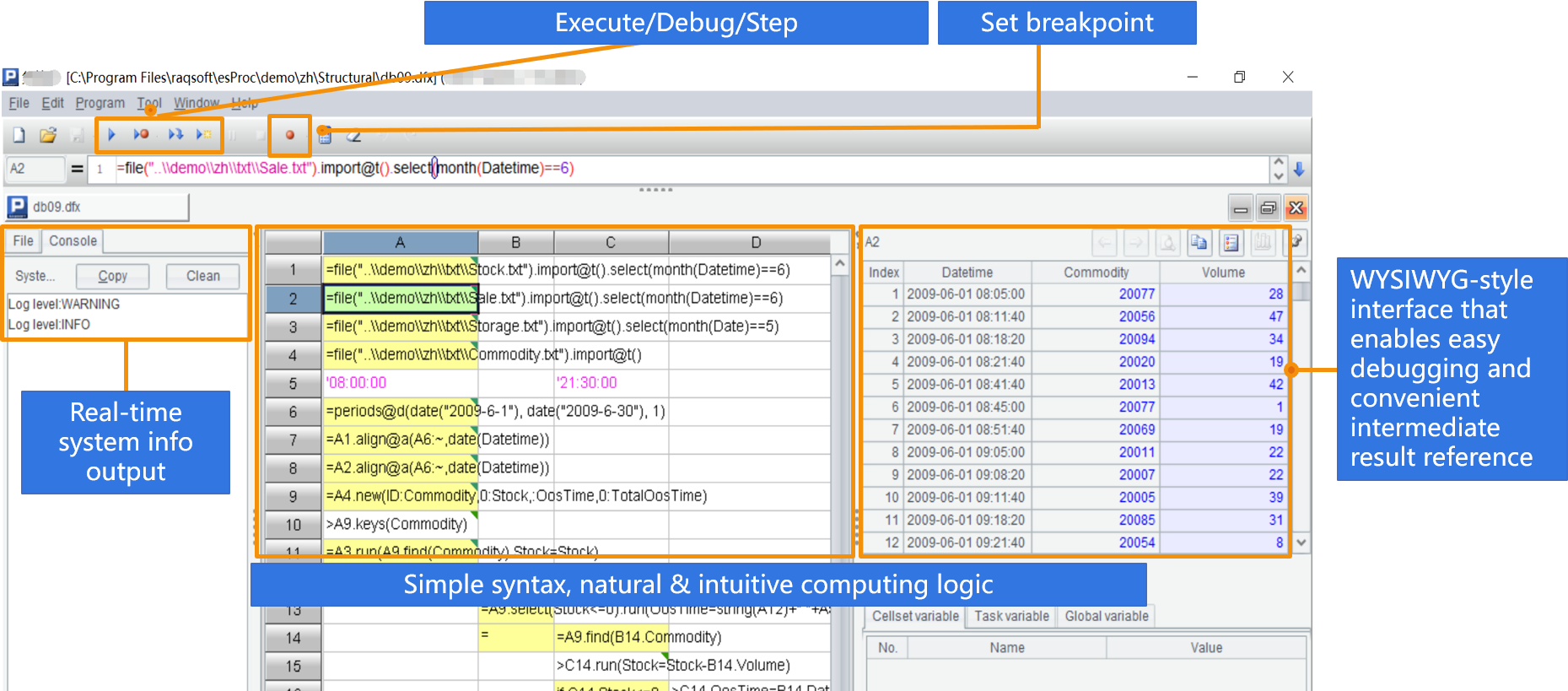
SPL is especially suitable for complex process operations.
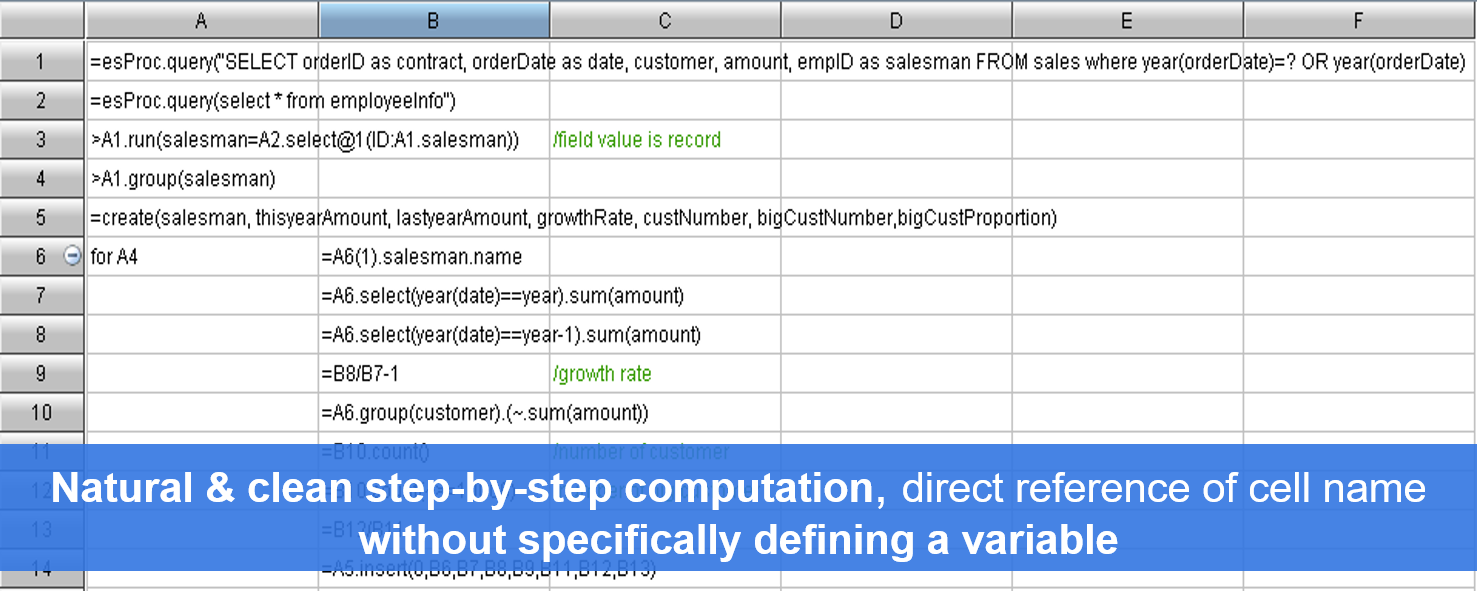
Intended for structured data processing

Multiple data sources are directly used for mixed calculation, and there is no need to unify the data (ETL) before calculation.

- Commercial RDBMS:Oracle, MS SQL Server, DB2, Informix
- Open Source RDBMS:MySQL, PostgreSQL
- Open Source NOSQL:MongoD, Redis, Cassandra, ElasticSearch
- Hadoop family:HDFS, HIVE, HBase
- Application software:SAP ECC, BW
- Files:Excel, Json, XML, TXT
- Others:Http Restful, Web Services, OLAP4j, ...
SPL is developed in Java and provides a standard application interface, and can be seamlessly integrated into applications.
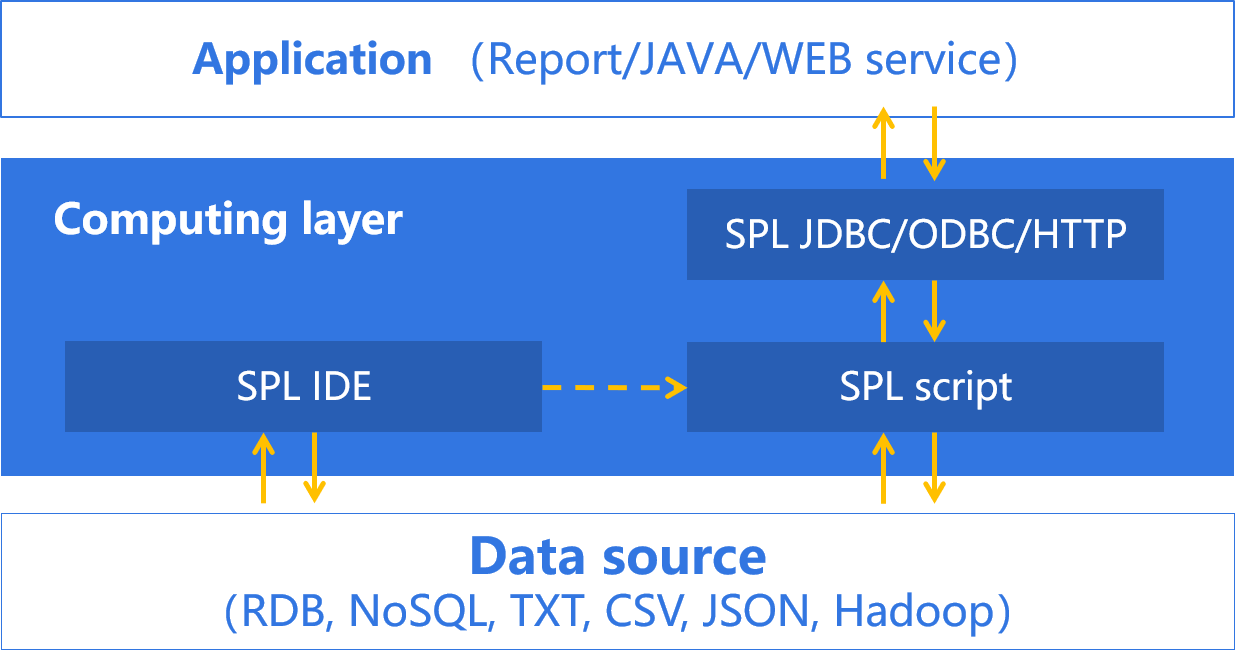
SPL interpreted execution supports hot switching.
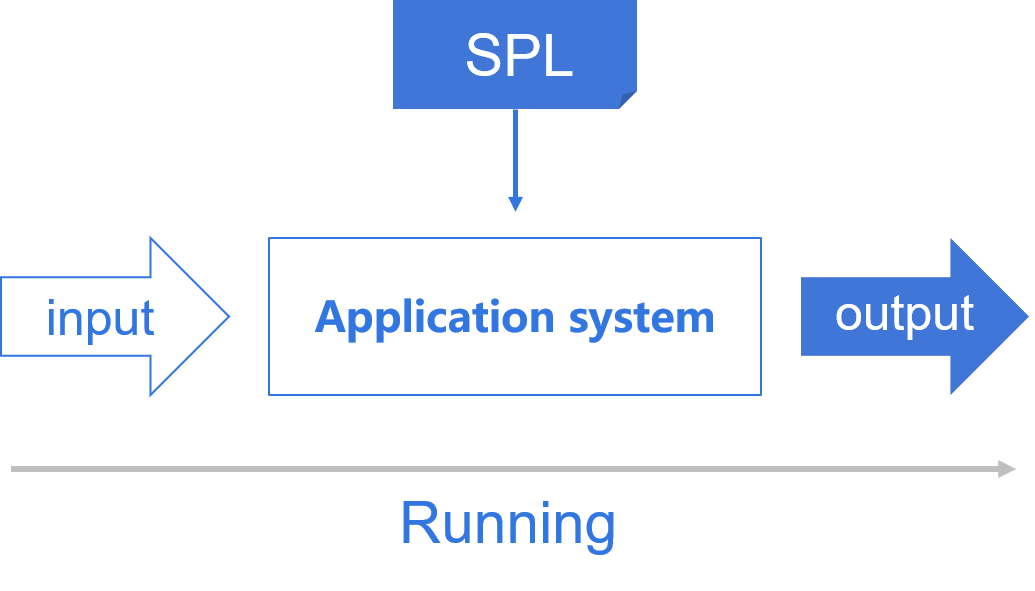
Easily implement multithreaded computing for a single task.
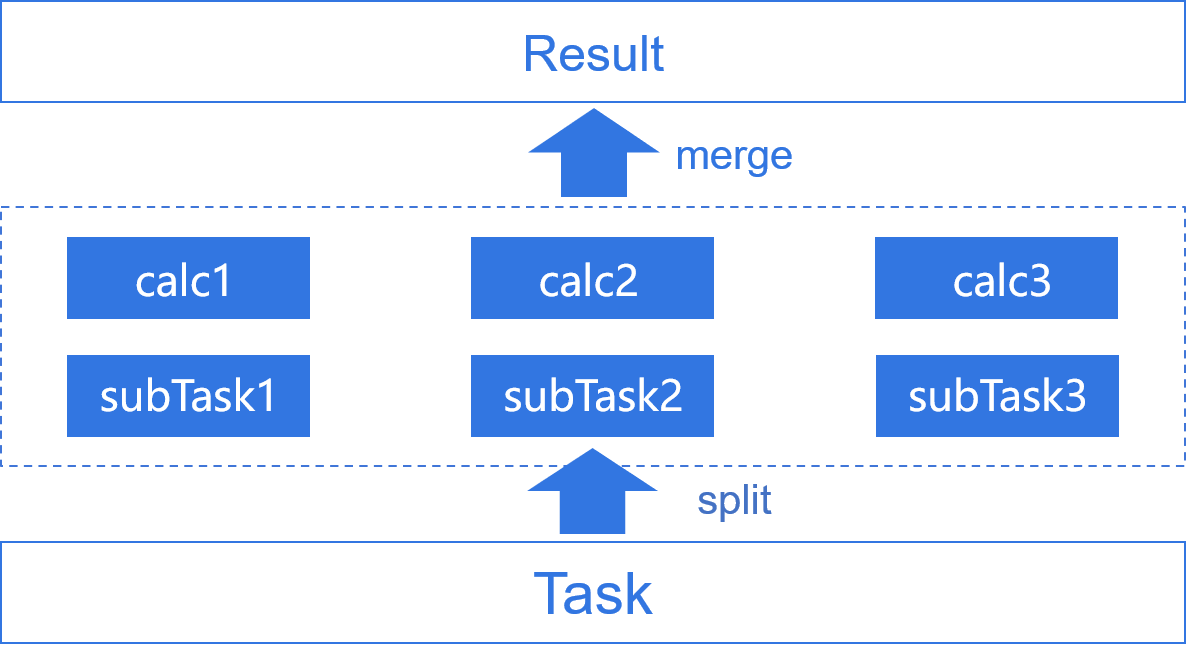
High performance data storage
Private data storage format : Bin file, composite table
File system storage
Support the storage of data by business classification in the form of tree directory
Bin file
- Double increment segmentation supports any number of parallel computing
- Privatehigh-efficiency compression coding (reducing space; less CPU consumption; security)
- Generic storage, allow set data
Composite table
- Row-based storage and columnar storage
- Orderly storage improves compression rate and positioning performance
- Efficient intelligent index
- Double increment segmentation supports any number of parallel computing
- Integration of primary and sub tables to reduce storage and association
- Using serial byte to achieve efficient positioning and association
Data fault tolerance and computing fault tolerance
Provide two data fault-tolerant mechanisms: external storage redundancy fault-tolerance and memory spare-tire fault-tolerance
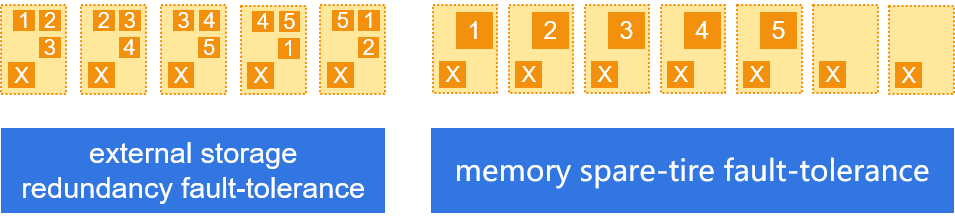
Support computing fault tolerance. When a node fails, it automatically migrates the computing tasks of the node to other nodes to continue to complete.
Controllable data distribution
Users can flexibly customize data distribution and redundancy scheme according to the characteristics of data and computing task, so as to effectively reduce the amount of data transmission between nodes and obtain higher performance.
No central architecture to avoid single point of failure
The cluster does not have a permanent central master node. Programmers use code to control the nodes involved in computing.
Load balancing capability
Whether to allocate tasks is determined according to the idle degree (number of threads) of each node to achieve an effective balance between burden and resources.