Python vs. SPL 9 Inverse Grouping & Transpose
When performing aggregation on the result of grouping operation, we usually get a set smaller than the original set, which equals to doing aggregation on the data; while inverse grouping is equivalent to the inverse operation of grouping, using a relatively small data table to calculate a bigger data table through certain regulations. And transpose operation is often referred to the transposition from row to column, which is in fact a variant of grouping operation; inverse transpose is a variant of inverse grouping. In this article, we’ll compare the calculation abilities of Python and SPL in inverse grouping and transpose operations.
In general, the data that are grouped and aggregated have lost their detailed information, so that they are not able to be inversely calculated. However, sometimes they can participate in inverse grouping operations according to certain regulations. For example:
List the customer’s repayment details (current repayment amount, current interest rate, current principle, and remaining principle included) according to the customer’s loan amount, repayment terms and interest rate. Part of the customer’s loan information are as follows:

Python
| import numpy as np
import pandas as pd loan_file="D:\data\loan.txt" loan_data=pd.read_csv(loan_file,sep='\t') loan_data['mrate']=loan_data['RATE']/(100*12)
loan_data['mpayment']=loan_data['AMOUNT']*loan_data['mrate']*np.power(1+loan_data['mrate'],loan_data['TERM']) /(np.power(1+loan_data['mrate'],loan_data['TERM'])-1)
loan_term_list = [] for i in range(len(loan_data)): tm=loan_data.loc[i]['TERM'] loanid=np.tile(loan_data.loc[i]['ID'],tm) loanamt=np.tile(loan_data.loc[i]['AMOUNT'],tm) term=np.tile(loan_data.loc[i]['TERM'],tm) rate=np.tile(loan_data.loc[i]['RATE'],tm) payment=np.tile(np.array(loan_data.loc[i]['mpayment']),tm) interest=np.zeros(tm) principal=np.zeros(tm) principalbalance=np.zeros(tm) loan_amt=loanamt[0] for j in range(tm): interest[j]=loan_amt*loan_data.loc[i]['mrate'] principal[j]=payment[j]-interest[j] principalbalance[j]=loan_amt-principal[j] loan_amt=principalbalance[j] loan_data_df=pd.DataFrame(np.transpose(np.array([loanid,loanamt,term,rate,payment,interest,principal,principalbalance])),columns=['loanid','loanamt','term','rate','payment','interest','principal','principalbalance']) loan_term_list.append(loan_data_df)
loan_term_pay=pd.concat(loan_term_list,ignore_index=True) print(loan_term_pay) |
Monthly interest rate Monthly repayment Loop through stomers Interest Current principle Remaining principle Create Dataframe Union all the customers |
In Python, we just hard-code step by step according to the formula of installment loan (borrowed from the Internet), and then union to generate Dataframe, which is quite plain and does not need to be further described.
SPL
| A | B | |
| 1 | D:\data\loan.txt | |
| 2 | =file(A1).import@t() | |
| 3 | =A2.derive(RATE/100/12:mRate,AMOUNT*mRate*power((1+mRate),TERM)/(power((1+mRate),TERM)-1):mPayment) | /calculate monthly interest rate and monthly repayment |
| 4 | =A3.news((t=AMOUNT,TERM);ID, AMOUNT,mPayment:payment,TERM,RATE,t*mRate:interest,payment-interest:principal,t=t-principal:principlebalance) | /inverse group |
SPL provides a news function for inverse grouping, which is actually a two-layer loop function. It first loops through A2, then the first parameter “term”; the parameter after the semicolon is essentially for the inner loop function, i.e., “t” is for the “TERM” layer, which also refers to the term of loan, and the repayment amount “t” will change at the beginning of each term.
Expanding columns to rows is a common expansion operation, for example:
The student score table is:

Expand the table to a score table with STUDENTID, SUBJECT, and SCORE.
Python
| score_file="D:\data\SCORES2.csv"
score_data=pd.read_csv(score_file) clm=score_data.columns[1:] subject_score=score_data.melt(id_vars="STUDENTID",value_vars=clm,var_name='SUBJECT',value_name="SCORE") print(subject_score) |
The columns to be expanded Expand columns to rows |
Python uses the melt function to perform the expansion from columns to rows.
SPL
| A | B | |
| … | … | |
| 6 | D:\data\SCORES2.csv | |
| 7 | =file(A6).import@tc() | |
| 8 | =A7.fname().m(2:) | /the columns to be expanded |
| 9 | =A7.news(A8;STUDENTID,~:SUBJECT,A7.~.field(~):SCORE) | /expand columns to rows |
SPL uses the news(...) function to perform the operation. The code is easy to write and demonstrates the nature of expanding columns to rows, i.e., the inverse operation of grouping. This kind of operation is so common that SPL provides a ready-made function for such operations, that is, pivot@r(), and the code is written like:
A9=A7.pivot@r(STUDENTID;SUBJECT,SCORE;${A8.concat@c()})
We can further simplify the code for the situation where other fields except STUDENTID need to be expanded:
A9=A7.pivot@r(STUDENTID;SUBJECT,SCORE)
In contrast to the previous example, sometimes we also perform the inverse operations of expansion, converting rows to columns, which is known as transpose. For example:
The student score table is:
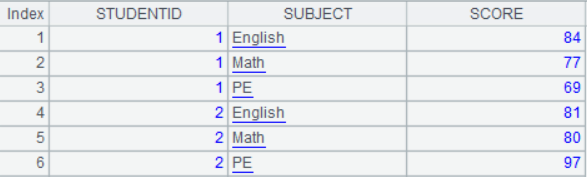
The calculation task is to organize the table to a score table with each subject as the heading.
Python
| score_file1="D:\data\SCORES1.csv"
score_data1=pd.read_csv(score_file1) scores=score_data1.pivot(index='STUDENTID',columns='SUBJECT',values='SCORE') print(scores) |
Transpose |
Python uses the pivot(...) function to perform the transpose operation, and the pivot and melt functions are inverse operations to each other.
SPL
| A | B | |
| … | … | |
| 11 | D:\data\SCORES1.csv | |
| 12 | =file(A11).import@tc() | |
| 13 | =A12.pivot(STUDENTID;SUBJECT,SCORE) | /transpose |
SPL can use the pivot function to easily perform the transpose operation, and the @r option of pivot function is the inverse operation of it, which has been introduced in last example. The transpose operation is a variant of grouping operation, and it can be also performed in the way of grouping in SPL:
A13=A12.group(STUDENTID;${A12.id(SUBJECT).("~.select@1(SUBJECT==\""+~+"\").SCORE:"+~).concat@c()})
Although the macro here is complicated, it can be fully understood if we think it through carefully. It means that the score in the current grouped subset which shares the same name of a certain subject is retrieved and used as the value of the subject field in the grouped table sequence. It is written in this way in order to demonstrate that the transpose operation is a variant of grouping, and in practice it can be done only using the pivot function.
Python provides no function for inverse grouping, the whole processing of which is done through hard-coding without any particular technique. In addition, the melt and pivot functions are inverse operations to each other, so it is convenient to convert between rows and columns.
The news function in SPL makes the inverse grouping much easier. With only one line of code, the complex inverse grouping can be successfully done: the @r option is added to pivot function to perform the transpose from rows to columns. Since we now clearly understand the relations between row-column conversion and grouping after studying this article, we can also find it not difficult to perform the row-column conversion with the grouping function “group” or inverse grouping function “news”.