
![]()

A Comprehensive Python Library for Deep Learning-Based Event Detection in Multivariate Time Series Data
- Introduction
- Installation
- Quickstart
- Make Prediction
- Documentation
- How to credit our package
- Futures Works
- References
Event detection in time series data is crucial in various domains, including finance, healthcare, cybersecurity, and science. Accurately identifying events in time series data is vital for making informed decisions, detecting anomalies, and predicting future trends. Despite extensive research exploring diverse methods for event detection in time series, with deep learning approaches being among the most advanced, there is still room for improvement and innovation in this field. In this paper, we present a new deep learning supervised method for detecting events in multivariate time series data. Our method combines four distinct novelties compared to existing deep-learning supervised methods. Firstly, it is based on regression instead of binary classification. Secondly, it does not require labeled datasets where each point is labeled; instead, it only requires reference events defined as time points or intervals of time. Thirdly, it is designed to be robust by using a stacked ensemble learning meta-model that combines deep learning models, ranging from classic feed-forward neural networks (FFNs) to state-of-the-art architectures like transformers. This ensemble approach can mitigate individual model weaknesses and biases, resulting in more robust predictions. Finally, to facilitate practical implementation, we have developed a Python package to accompany our proposed method. The package, called eventdetector-ts, can be installed through the Python Package Index (PyPI). In this paper, we present our method and provide a comprehensive guide on the usage of the package. We showcase its versatility and effectiveness through different real-world use cases from natural language processing (NLP) to financial security domains.

Before installing this package, please ensure that you have TensorFlow installed in your environment. This package relies on TensorFlow for its functionality, but does not include it as a dependency to allow users to manage their own TensorFlow installations. You can install TensorFlow via pip with pip install tensorflow.
Once TensorFlow is installed, you can proceed with the installation of this package. Please follow the instructions below:
pip install eventdetector-ts
To get started using Event Detector, simply follow the instructions below to install the required packages and dependencies.
git clone https://github.com/menouarazib/eventdetector.git
cd eventdetector
python -m venv env
source env/bin/activate # for Linux/MacOS
env\Scripts\activate.bat # for Windows
pip install -r requirements.txtTo quickly get started with EventDetector, follow the steps below:
- You can either download the datasets and event catalogs manually or use the built-in methods for the desired application:
- Bow Shock Crossings:
eventdetector_ts.load_martian_bow_shock() - Credit Card Frauds:
eventdetector_ts.load_credit_card_fraud() - NLP:
- Bow Shock Crossings:
- Credit Card Frauds:
from eventdetector_ts import load_credit_card_fraud, FFN
from eventdetector_ts.metamodel.meta_model import MetaModel
dataset, events = load_credit_card_fraud()
meta_model = MetaModel(dataset=dataset, events=events, width=2, step=1,
output_dir='credit_card_fraud', batch_size=3200, s_h=0.01, models=[(FFN, 1)],
hyperparams_ffn=(1, 1, 20, 20, "sigmoid"))
meta_model.fit()- Martian Bow Shock:
from eventdetector_ts import load_martian_bow_shock, FFN
from eventdetector_ts.metamodel.meta_model import MetaModel
dataset, events = load_martian_bow_shock()
meta_model = MetaModel(output_dir="mex_bow_shocks", dataset=dataset, events=events, width=76, step=1,
time_window=5400.0, batch_size=3000, models=[(FFN, 1)],
hyperparams_ffn=(1 , 1, 20, 20, "sigmoid"))
meta_model.fit()| Method | Number of Parameters | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN [1] | 119,457 | 0.89 | 0.68 | 0.77 |
| FFN+SMOTE [2] | 5,561 | 0.79 | 0.81 | 0.80 |
| FFN+SMOTE [3] | N/A | 0.82 | 0.79 | 0.81 |
| Ours | 1,201 | 0.98 | 0.74 | 0.85 |
| Method | Number of Parameters | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet18 [4] | 29,886,979 | 0.99 | [0.83 , 0.88] | [0.91 , 0.94] |
| Ours | 6,121 | 0.95 | 0.96 | 0.95 |
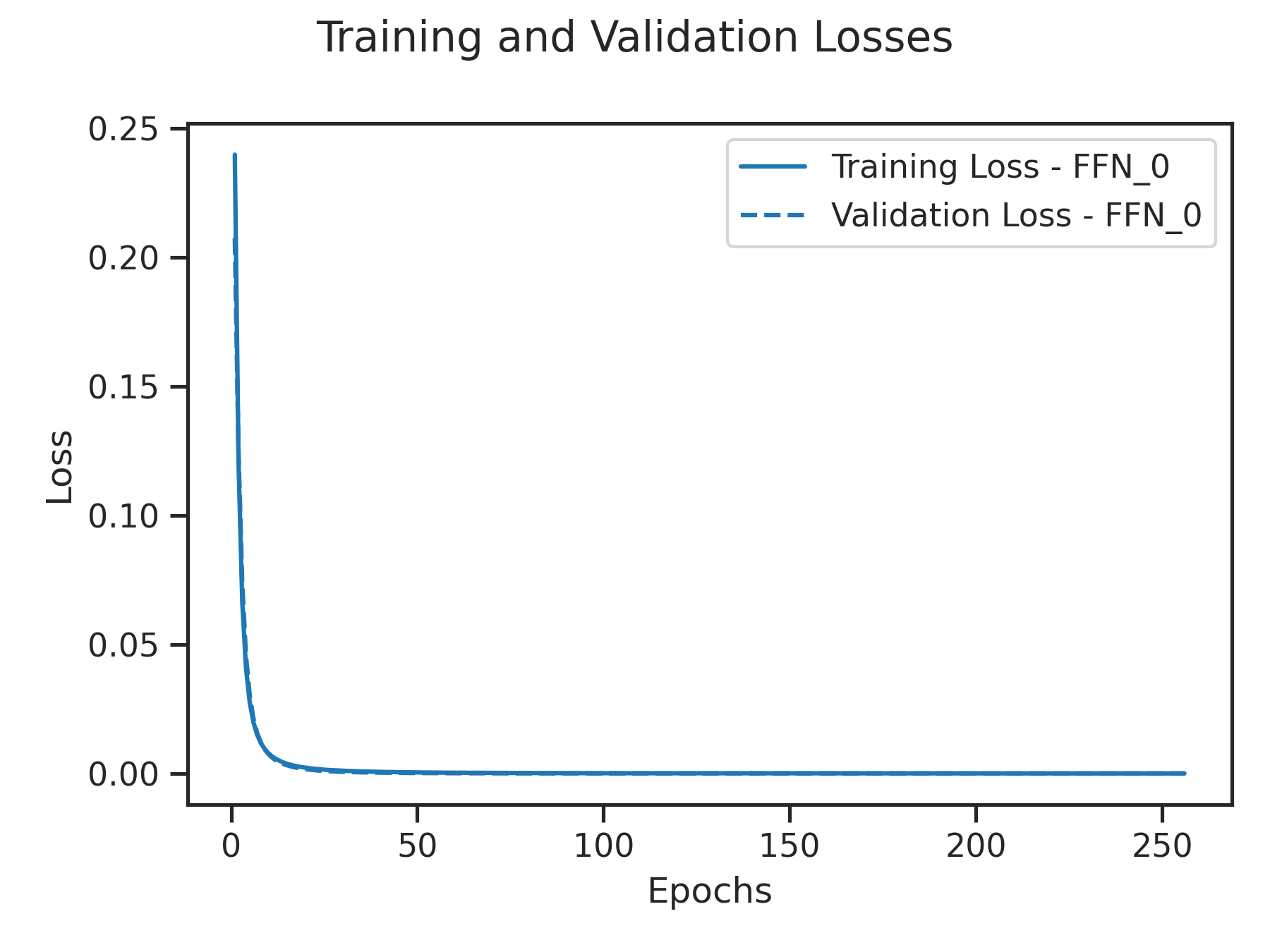
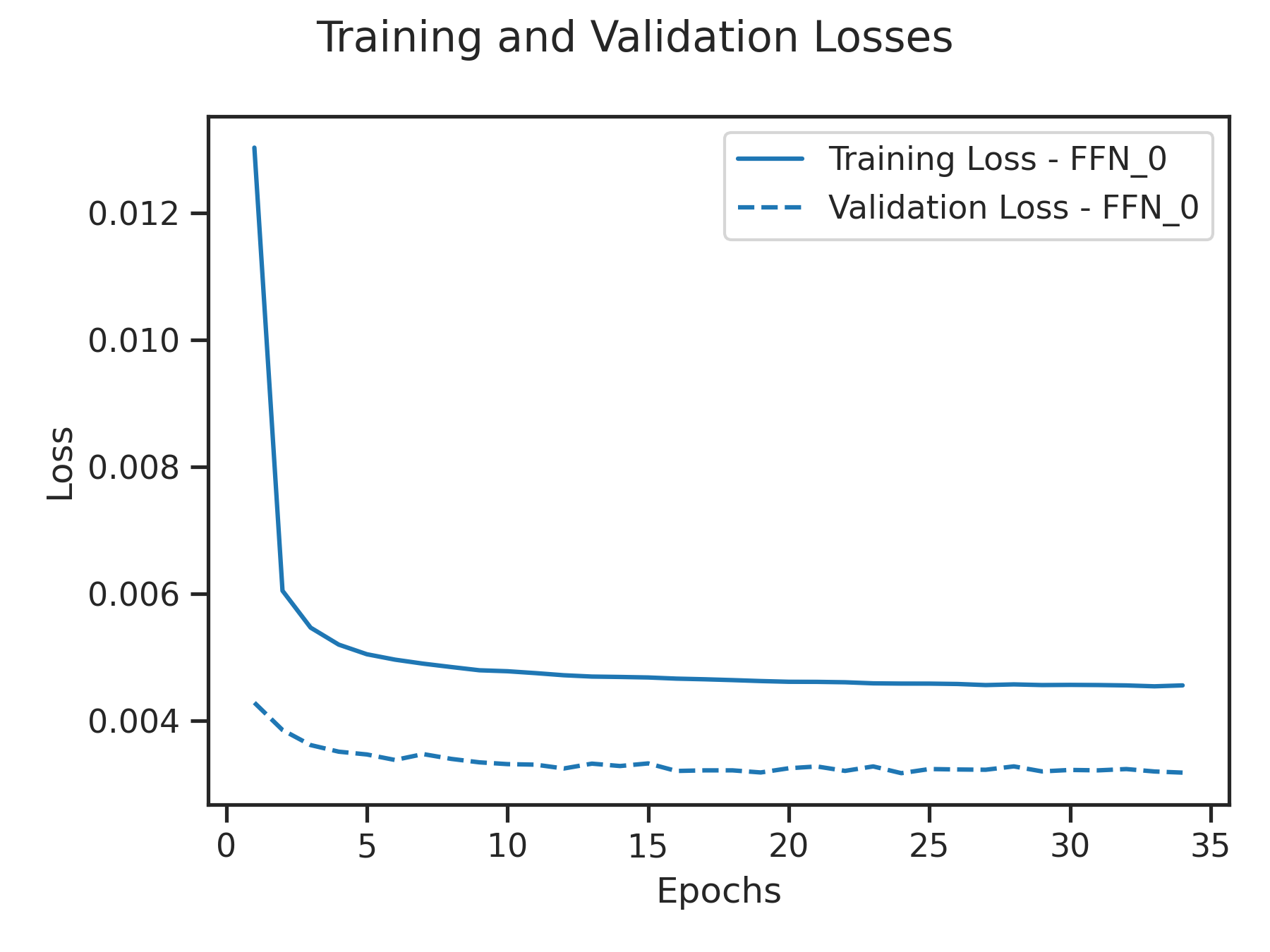
The Figure below showcases the training loss and validation loss of the FFNs on the Bow Shock Crossings and Credit Card Frauds. The low losses observed in both cases indicate that the metamodel has successfully learned the underlying patterns, justifying the obtained good metrics.
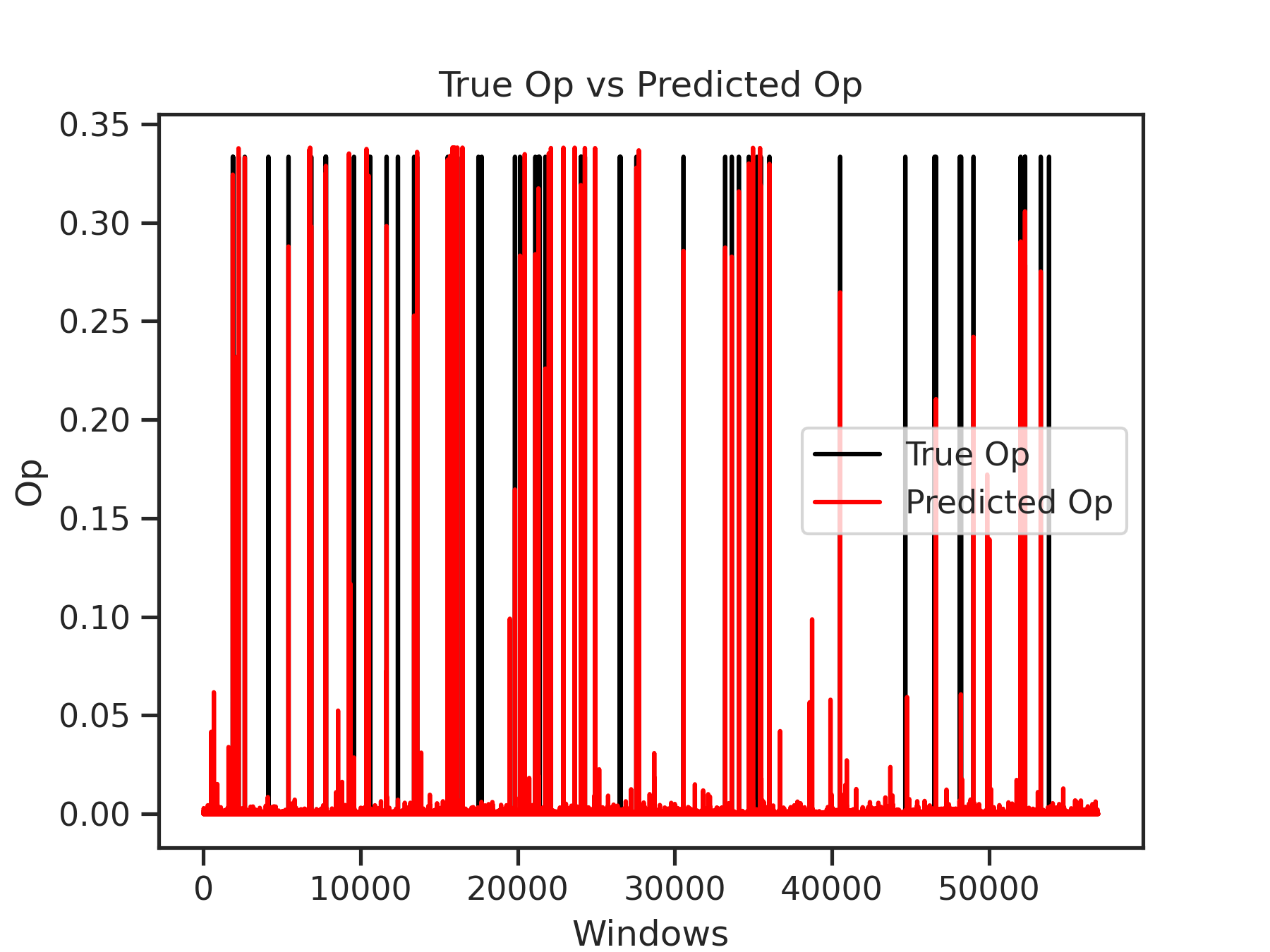
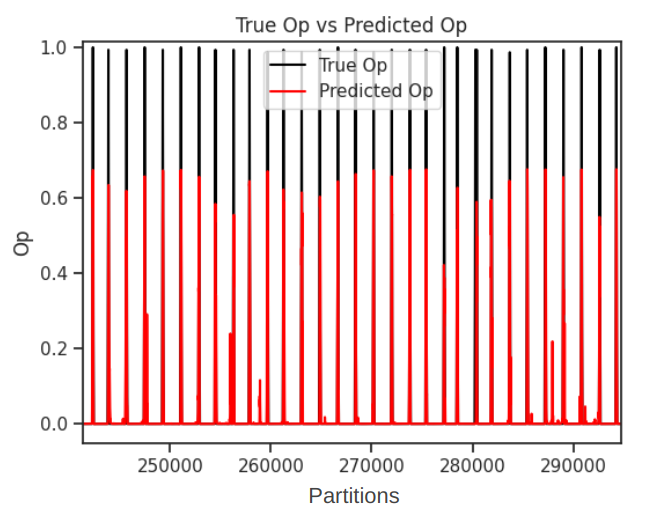
The Figure below illustrates the comparison between the predicted
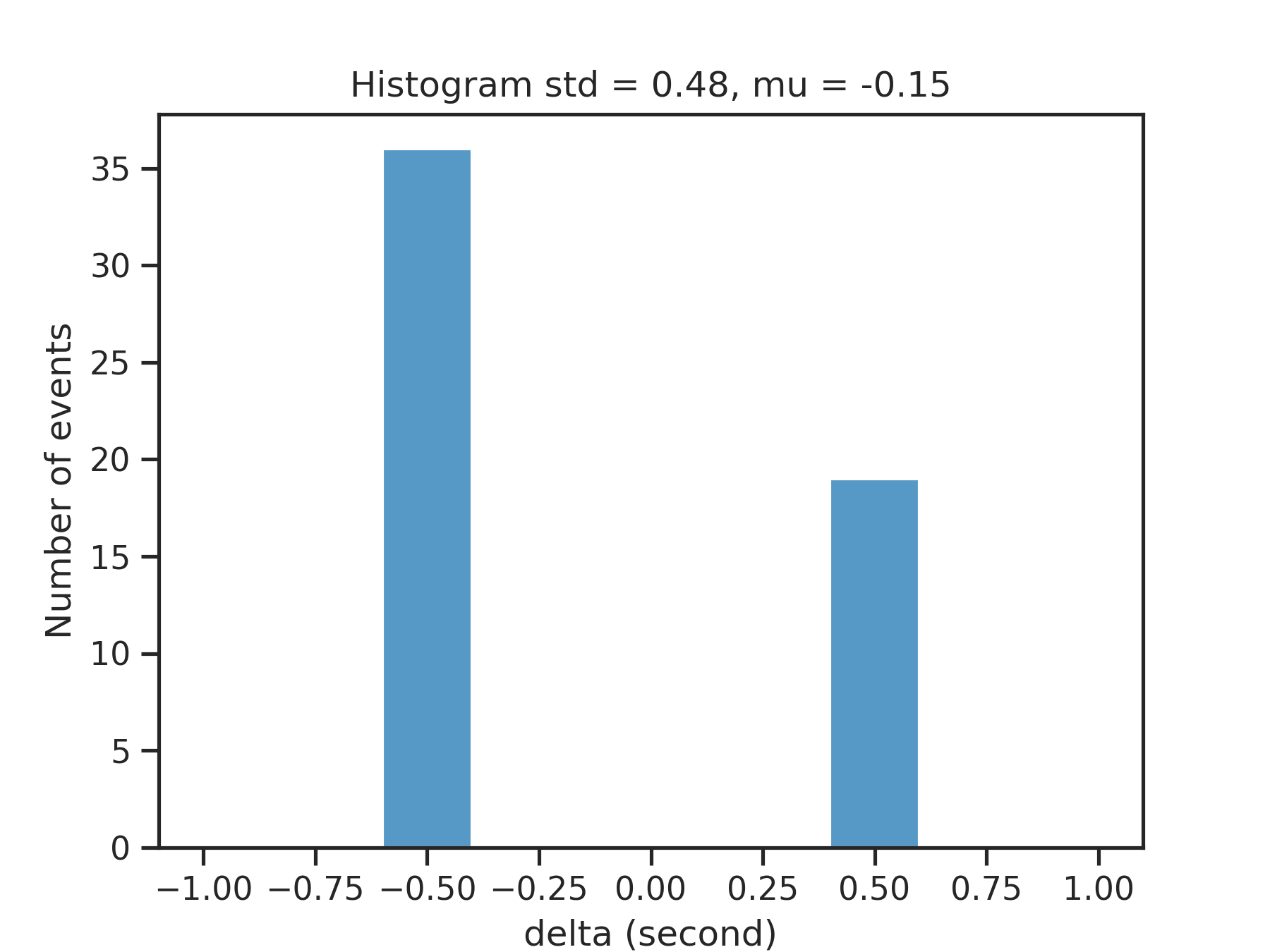
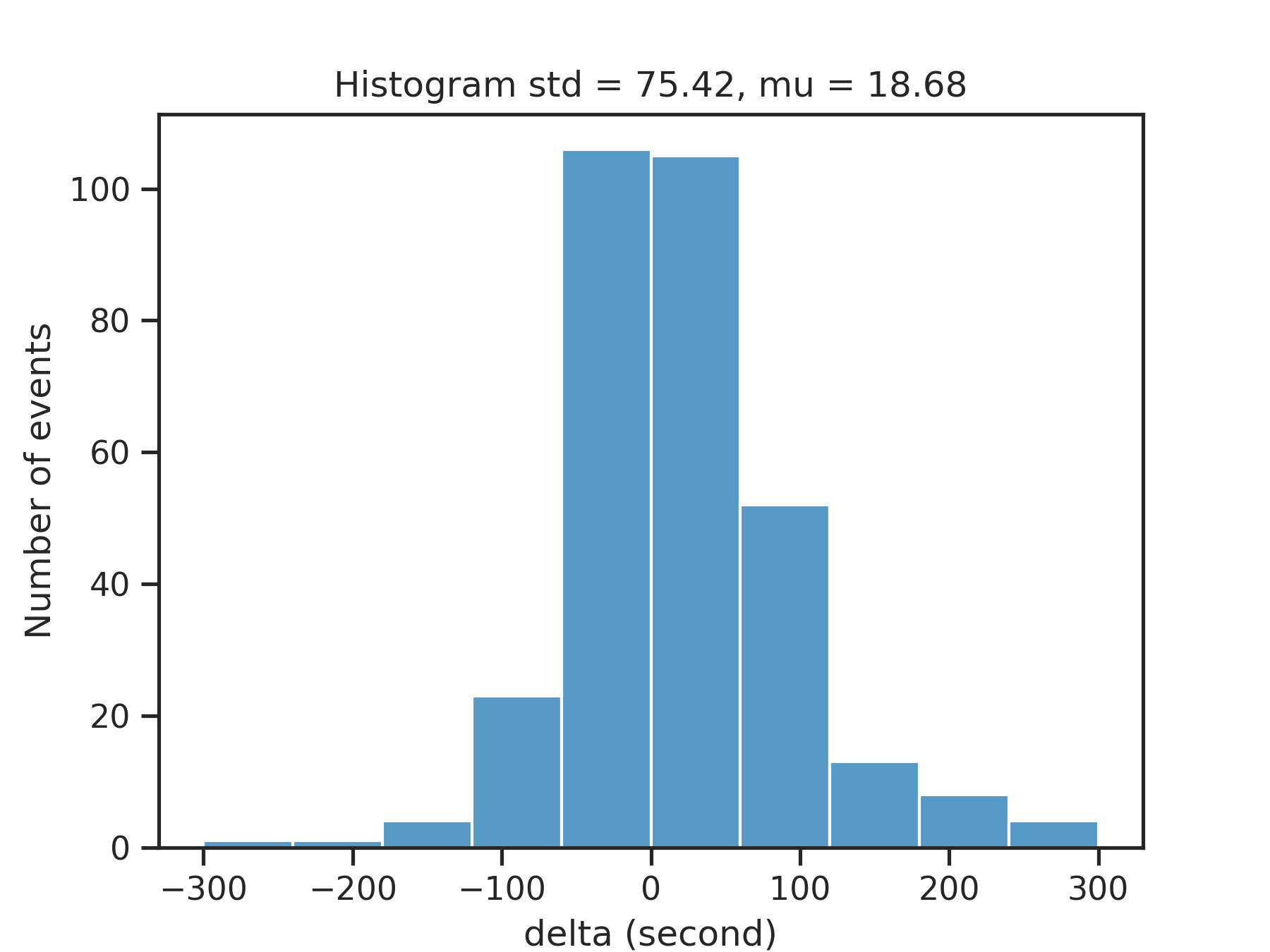
Distribution of time differences δ(t) between predicted events and ground truth events for Bow Shock Crossings and Credit Card Frauds
from eventdetector_ts.prediction.prediction import predict
from eventdetector_ts.prediction.utils import plot_prediction
dataset_for_prediction = ...
# Call the 'predict' method
predicted_events, predicted_op, filtered_predicted_op = predict(dataset=dataset_for_prediction,
path='path to output_dir')
# Plot the predictions
plot_prediction(predicted_op=predicted_op, filtered_predicted_op=filtered_predicted_op)For a deeper understanding of the parameters presented below, please refer to our paper available at this link.
The first step is to instantiate the MetaModel object with the required arguments:
from eventdetector_ts.metamodel.meta_model import MetaModel
meta_model = MetaModel(output_dir=..., dataset=..., events=..., width=..., step=...)For a complete description of the required and optional arguments, please refer to the following tables:
| Argument | Type | Description | Default Value |
|---|---|---|---|
output_dir |
str | The name or path of the directory where all outputs will be saved. If output_dir is a folder name, the full path in the current directory will be created. |
- |
dataset |
pd.DataFrame | The input dataset as a Pandas DataFrame. | - |
events |
Union[list, pd.DataFrame] | The input events as either a list or a Pandas DataFrame. | - |
width |
int | Number of consecutive time steps in each partition (window) when creating overlapping partitions (sliding windows). | - |
step |
int | Number of time steps to advance the sliding window. | 1 |
width_events |
Union[int, float] | The width of each event. If it's an ìnt, it represents the number of time steps that constitute an event. If it's a float, it represents the duration in seconds of each event. If not provided (None), it defaults to the value of width -1. |
width -1 |
| Argument | Type | Description | Default Value |
|---|---|---|---|
t_max |
float | The maximum total time is linked to the sigma variable of the Gaussian filter. This time should be expressed in the same unit of time (seconds, minutes, etc.) as used in the dataset. The unit of time for the dataset is determined by its time sampling. In other words, the sigma variable should align with the timescale used in your time series data. |
(3 x (width -1) x time_sampling) / 2 |
delta |
Union[int, float] | The maximum time tolerance used to determine the correspondence between a predicted event and its actual counterpart in the true events. If it's an integer, it represents the number of time steps. If it's a float, it represents the duration in seconds. | width_events x time_sampling |
s_h |
float | A step parameter for adjusting the peak height threshold h during the peak detection process. |
0.05 |
epsilon |
float | A small constant used to control the size of set which contains the top models with the lowest MSE values. | 0.0002 |
pa |
int | The patience for the early stopping algorithm. | 5 |
t_r |
float | The ratio threshold for the early stopping algorithm. | 0.97 |
time_window |
Union[int, float] | This parameter controls the amount of data within the dataset is used for the training process. If it's an integer, it represents a specific number time steps. If it's a float, it represents a duration in seconds. By default, it is set to None, which means all available data will be used. However, if a value is provided, the dataset will include a specific interval of data surrounding each reference event. This interval includes data from both sides of each event, with a duration equal to the specified time_window. Setting a time_window in some situations can offer several advantages, such as accelerating the training process and enhancing the neural networks' understanding of rare events. |
None |
models |
List[Union[str, Tuple[str, int]]] | Determines the type of deep learning models and the number of instances to use. Available models: LSTM, GRU, CNN, RNN_BIDIRECTIONAL, RNN_ENCODER_DECODER, CNN_RNN, FFN, CONV_LSTM1D, SELF_ATTENTION, TRANSFORMER. |
[(FFN, 2)] |
hyperparams_ffn |
Tuple[int, int, int, int, str] | Specify for the FFN the minimum and the maximum number of layers, the minimum and the maximum number of neurons per layer, and the activation function. The List of available activation functions are ["relu","sigmoid","tanh","softmax","leaky_relu","elu","selu","swish"]. If you pass None, no activation is applied (i.e. "linear" activation: a(x) = x). |
(1, 3, 64, 256, "sigmoid") |
hyperparams_cnn |
Tuple[int, int, int, int, int, int, str] | Specify for the CNN the minimum and maximum number of filters, the minimum and the maximum kernel size, the minimum and maximum number of pooling layers, and the activation function. | (16, 64, 3, 8 , 1, 2, "relu") |
hyperparams_transformer |
Tuple[int, int, int, bool, str] | Specify for Transformer the Key dimension, number of heads, the number of the encoder blocks, a flag to indicate the use of the original architecture, and the activation function. | (256, 8, 10, True, "relu") |
hyperparams_rnn |
Tuple[int, int, int, int, str] | Specify for the RNN the minimum and maximum number of recurrent layers,the minimum and the maximum number of hidden units, and the activation function. | (1,2, 16, 128,"tanh") |
hyperparams_mm_network |
Tuple[int,int,str] | Specify for the MetaModel network the number of layers,the number of neurons per layer, and the activation function. | (1 ,32,"sigmoid") |
epochs |
int | The number of epochs to train different models. | 256 |
batch_size |
int | The number of samples per gradient update. | 32 |
fill_nan |
str | Specifies the method to use for filling NaN values in the dataset. Supported methods are 'zeros', 'ffill', 'bfill', and 'median'. |
"zeros" |
type_training |
str | Specifies the type of training technique to use for the MetaModel. Supported techniques are 'average' and 'ffn'. | "average" |
scaler |
str | The type of scaler to use for preprocessing the data. Possible values are "MinMaxScaler", "StandardScaler", and "RobustScaler". | "StandardScaler" |
use_kfold |
bool | Whether to use k-fold cross-validation technique or not. | False |
test_size |
float | The proportion of the dataset to include in the test split. Should be a value between 0 and 1. | 0.2 |
val_size |
float | The proportion of the training set to use for validation. Should be a value between 0 and 1. | 0.2 |
save_models_as_dot_format |
bool | Whether to save the models as a dot format file. If set to True, then you should have graphviz software installed on your machine. | False |
remove_overlapping_events |
bool | Whether to remove the overlapping events or not. | True |
dropout |
float | The dropout rate, which determines the fraction of input units to drop during training. | 0.3 |
last_act_func |
str | Activation function for the final layer of each model. If set to None, no activation will be applied (i.e., "linear" activation: a(x) = x). |
"sigmoid" |
The method fit calls automatically the following methods:
The second thing to do is to prepare the events and the dataset for computing op:
meta_model.prepare_data_and_computing_op()The third thing to do is to build a stacking learning pipeline using the provided models and hyperparameters:
meta_model.build_stacking_learning()The fourth thing to do is to run the Event Extraction Optimization process:
meta_model.event_extraction_optimization()Finally, you can plot the results, which are saved automatically: losses, true/predicted ops, true/predicted events, and delta_t.
meta_model.plot_save(show_plots=True)If you use our package, please cite the following papers:
@INPROCEEDINGS{10459857,
author={Azib, Menouar and Renard, Benjamin and Garnier, Philippe and Génot, Vincent and André, Nicolas},
booktitle={2023 International Conference on Machine Learning and Applications (ICMLA)},
title={A Comprehensive Python Library for Deep Learning-Based Event Detection in Multivariate Time Series Data},
year={2023},
volume={},
number={},
pages={1399-1404},
keywords={Deep learning;Technological innovation;Event detection;Time series analysis;Predictive models;Tagging;Transformers;Event Detection in Time Series;Regression;Python Package;Information Retrieval;Natural Language Pro-cessing (NLP)},
doi={10.1109/ICMLA58977.2023.00211}
}In our future works, we aim to enhance our model’s capabilities by predicting events of varying durations. This would be a significant improvement over our current approach, which only predicts the midpoint of events with a fixed duration.
[3] E. Ileberi, Y. Sun and Z. Wang, “A machine learning based credit card fraud detection using the GA algorithm for feature selection,” in J Big Data, vol. 9, no. 24, 2022. [Online]. Available: https://doi.org/10.1186/s40537-022-00573-8.