This is a Keras implementation of a CNN for estimating age and gender from a face image [1, 2]. In training, the IMDB-WIKI dataset is used.
- Python3.5+
- Keras2.0+
- scipy, numpy, Pandas, tqdm, tables, h5py
- dlib (for demo)
- OpenCV3
Tested on:
- Ubuntu 16.04, Python 3.5.2, Keras 2.0.3, Tensorflow(-gpu) 1.0.1, Theano 0.9.0, CUDA 8.0, cuDNN 5.0
- CPU: i7-7700 3.60GHz, GPU: GeForce GTX1080
- macOS Sierra, Python 3.6.0, Keras 2.0.2, Tensorflow 1.0.0, Theano 0.9.0
Download pretrained model weights for TensorFlow backend:
mkdir -p pretrained_models
wget -P pretrained_models https://www.dropbox.com/s/rf8hgoev8uqjv3z/weights.18-4.06.hdf5Run demo script (requires web cam)
python3 demo.pyModel weights for Theano backend is also available from here.
The dataset is downloaded and extracted to the data directory.
./download.shFilter out noise data and serialize images and labels for training into .mat file.
Please check check_dataset.ipynb for the details of the dataset.
python3 create_db.py --output data/imdb_db.mat --db imdb --img_size 64usage: create_db.py [-h] --output OUTPUT [--db DB] [--img_size IMG_SIZE] [--min_score MIN_SCORE]
This script cleans-up noisy labels and creates database for training.
optional arguments:
-h, --help show this help message and exit
--output OUTPUT, -o OUTPUT path to output database mat file (default: None)
--db DB dataset; wiki or imdb (default: wiki)
--img_size IMG_SIZE output image size (default: 32)
--min_score MIN_SCORE minimum face_score (default: 1.0)Train the network using the training data created above.
python3 train.py --input data/imdb_db.matTrained weight files are stored as checkpoints/weights.*.hdf5 for each epoch if the validation loss becomes minimum over previous epochs.
usage: train.py [-h] --input INPUT [--batch_size BATCH_SIZE]
[--nb_epochs NB_EPOCHS] [--depth DEPTH] [--width WIDTH]
[--validation_split VALIDATION_SPLIT] [--aug]
This script trains the CNN model for age and gender estimation.
optional arguments:
-h, --help show this help message and exit
--input INPUT, -i INPUT
path to input database mat file (default: None)
--batch_size BATCH_SIZE
batch size (default: 32)
--nb_epochs NB_EPOCHS
number of epochs (default: 30)
--depth DEPTH depth of network (should be 10, 16, 22, 28, ...)
(default: 16)
--width WIDTH width of network (default: 8)
--validation_split VALIDATION_SPLIT
validation split ratio (default: 0.1)
--aug use data augmentation if set true (default: False)Recent data augmentation methods, mixup [3] and Random Erasing [4],
can be used with standard data augmentation by --aug option in training:
python3 train.py --input data/imdb_db.mat --augPlease refer to this repository for implementation details.
I confirmed that data augmentation enables us to avoid overfitting and improves validation loss.
python3 demo.pyusage: demo.py [-h] [--weight_file WEIGHT_FILE] [--depth DEPTH] [--width WIDTH]
This script detects faces from web cam input, and estimates age and gender for
the detected faces.
optional arguments:
-h, --help show this help message and exit
--weight_file WEIGHT_FILE path to weight file (e.g. weights.18-4.06.hdf5) (default: None)
--depth DEPTH depth of network (default: 16)
--width WIDTH width of network (default: 8)
Please use the best model among checkpoints/weights.*.hdf5 for WEIGHT_FILE if you use your own trained models.
python3 plot_history.py --input models/history_16_8.h5 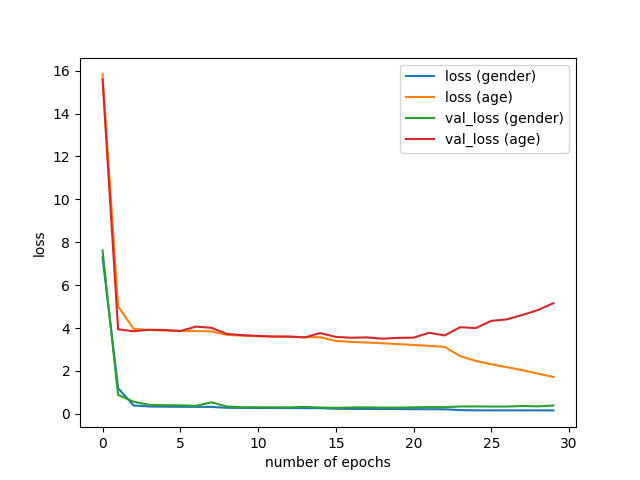

The best val_loss was improved from 3.969 to 3.731:
- Without data augmentation: 3.969
- With standard data augmentation: 3.799
- With mixup and random erasing: 3.731

We can see that, with data augmentation, overfitting did not occur even at very small learning rates (epoch > 15).
In the original paper [1, 2], the pretrained VGG network is adopted. Here the Wide Residual Network (WideResNet) is trained from scratch. I modified the @asmith26's implementation of the WideResNet; two classification layers (for age and gender estimation) are added on the top of the WideResNet.
Note that while age and gender are independently estimated by different two CNNs in [1, 2], in my implementation, they are simultaneously estimated using a single CNN.
Trained on imdb, tested on wiki.

[1] R. Rothe, R. Timofte, and L. V. Gool, "DEX: Deep EXpectation of apparent age from a single image," ICCV, 2015.
[2] R. Rothe, R. Timofte, and L. V. Gool, "Deep expectation of real and apparent age from a single image without facial landmarks," IJCV, 2016.
[3] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, "mixup: Beyond Empirical Risk Minimization," in arXiv:1710.09412, 2017.
[4] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, "Random Erasing Data Augmentation," in arXiv:1708.04896, 2017.