Spring offers the pieces you need to add metrics and tracing to your Spring applications. This tutorial walks through how to create such an application.
|
Note
|
You can find all the code for this tutorial in the Spring Metrics and Tracing tutorial repository. |
|
Note
|
This tutorial is based on a blog post by Tommy Ludwig and Josh Long. |
For this example, we need two applications.
We call the first one service and the second one client.
Consequently, we need a parent build file that builds both applications:
link:basic/pom.xml[role=include]To start creating the service application, visit start.spring.io, choose Maven and Java 15, and set the Artifact field to service.
(You could use Gradle or Java 8 or Java 11, but this tutorial uses Maven and Java 8.)
Then add the following dependencies:
-
Spring Reactive Web
-
Spring Boot Actuator
-
Lombok
-
Sleuth
-
Wavefront
The following link sets all those options: start.spring.io.
These settings generate the following pom.xml file:
link:basic/service/pom.xml[role=include]The service application needs to have some application properties set.
In particular, we need to set the port to 8083 and set the application name to service.
(We explain the other two settings as they become relevant.)
Consequently, we need the following application.properties file:
link:basic/service/src/main/resources/application.properties[role=include]Now we can write that actual application:
link:basic/service/src/main/java/server/ServiceApplication.java[role=include]Given a request for a particular type of console (PS5, Nintendo, Xbox, or PS4), the API returns the console’s availability (presumably sourced from local electronics outlets). So that we can demonstrate an error, PlayStation 5 is never available. Also, the service itself throws an error when someone inquires about the Playstation 5. We use this particular code path (asking about the availability of Playstation 5) to simulate an error.
We want as much information as possible about individual microservices and their interactions, and we most want that information when we try to find bugs in the system. This arrangement lets us see how tracing and metrics can work together to provide an observability posture that is superior to using either metrics or tracing alone.
Now we need a client application to exercise the service application.
We start by using start.spring.io to create the pom.xml file for the client application.
We need the same settings and dependencies as the service application, but we change the artifact ID to client.
The following link sets all those values: start.spring.io.
The result is the following pom.xml file:
link:basic/client/pom.xml[role=include]The client application needs a slightly different set of application properties, which we set in the application.properties file:
link:basic/client/src/main/resources/application.properties[role=include]
For the client, we need not set the port.
Now we can create the client application code:
link:basic/client/src/main/java/server/ClientApplication.java[role=include]
The code uses the reactive, non-blocking WebClient to issue requests against the service.
The entire application, both client and service, uses reactive, non-blocking HTTP.
You could just as easily use the traditional servlet-based Spring MVC.
You could also avoid HTTP altogether and use messaging technologies or some combination of those technologies.
Now that we have both applications, we can run them. Start the service application. Note the Wavefront URL in the console output from the service application. Paste that URL into a web browser, so that you can see the Wavefront dashboard for the application. (You want to get that URL before you start the client application, as the client application intentionally creates a number of errors that create a lot of console output.)
Now you can start the client application.
The client application generates data that, after a minute or so, appears in the Wavefront dashboard.
As noted earlier, the client application also generates a number of errors, each with the following message: 500 Server Error for HTTP GET "/availability/ps5".
Those errors let us model what happens when an application produces errors.
As you saw when we created the applications, we included Spring Boot Actuator and Sleuth.
Spring Boot Actuator brings in Micrometer, which provides a simple facade over the instrumentation clients for the most popular monitoring systems, letting you instrument your JVM-based application code without vendor lock-in. Think “SLF4J for metrics”.
The most straightforward use of Micrometer is to capture metrics and keep them in memory, which Spring Boot Actuator does.
You can configure your application to show those metrics under an Actuator management endpoint: /actuator/metrics/. More commonly, though, you want to send these metrics to a time-series database, such as Graphite, Prometheus, Netflix Atlas, Datadog, or InfluxDB.
Time series databases store the evolving value of a metric over time, so you can see how it has changed.
We also want to have detailed breakdowns of individual requests and traces to give us context around particular failed requests. The Sleuth starter brings in the Spring Cloud Sleuth distributed tracing abstraction, which provides a simple facade over distributed tracing systems, such as OpenZipkin and Google Cloud Stackdriver Trace and Wavefront.
Micrometer and Sleuth give you the power of choice in metrics and tracing backends. We could use these two different abstractions and separately stand up a dedicated cluster for our tracing and metrics aggregation systems. Because these tools do not tie you to a particular vendor, they give you a lot of flexibility around how you build your tracing and metrics framework.
Now we can see what is happening to our application in Wavefront. Paste the Wavefront URL that you copied earlier into a browser.
|
Note
|
Wavefront has a lot of capabilities. We touch on only those capabilities that matter for this example. |
The URL is to a free demo account for Wavefront. It has a limited lifespan, so it cannot support a production application, but it works for a demonstration.
The following image shows the starting page of the Wavefront dashboard for our application:
Wavefront comes fully loaded with a Spring Boot dashboard in the Dashboards menu at the top of the screen.
The top of the dashboard shows that the source is my-cloud-server, which comes from the management.export.wavefront.source configuration property (or you can use the default, which is the hostname of the machine).
The application we care about is console-availability, which comes from the wavefront.application.name configuration property.
“Application” refers to the logical group of Spring Boot microservices rather than any specific application.
Click on console-availability to see everything about your application at a glance.
You can look at information for either module: client or service.
Click Jump To to navigate to a particular set of graphs.
We want the data in the HTTP section.
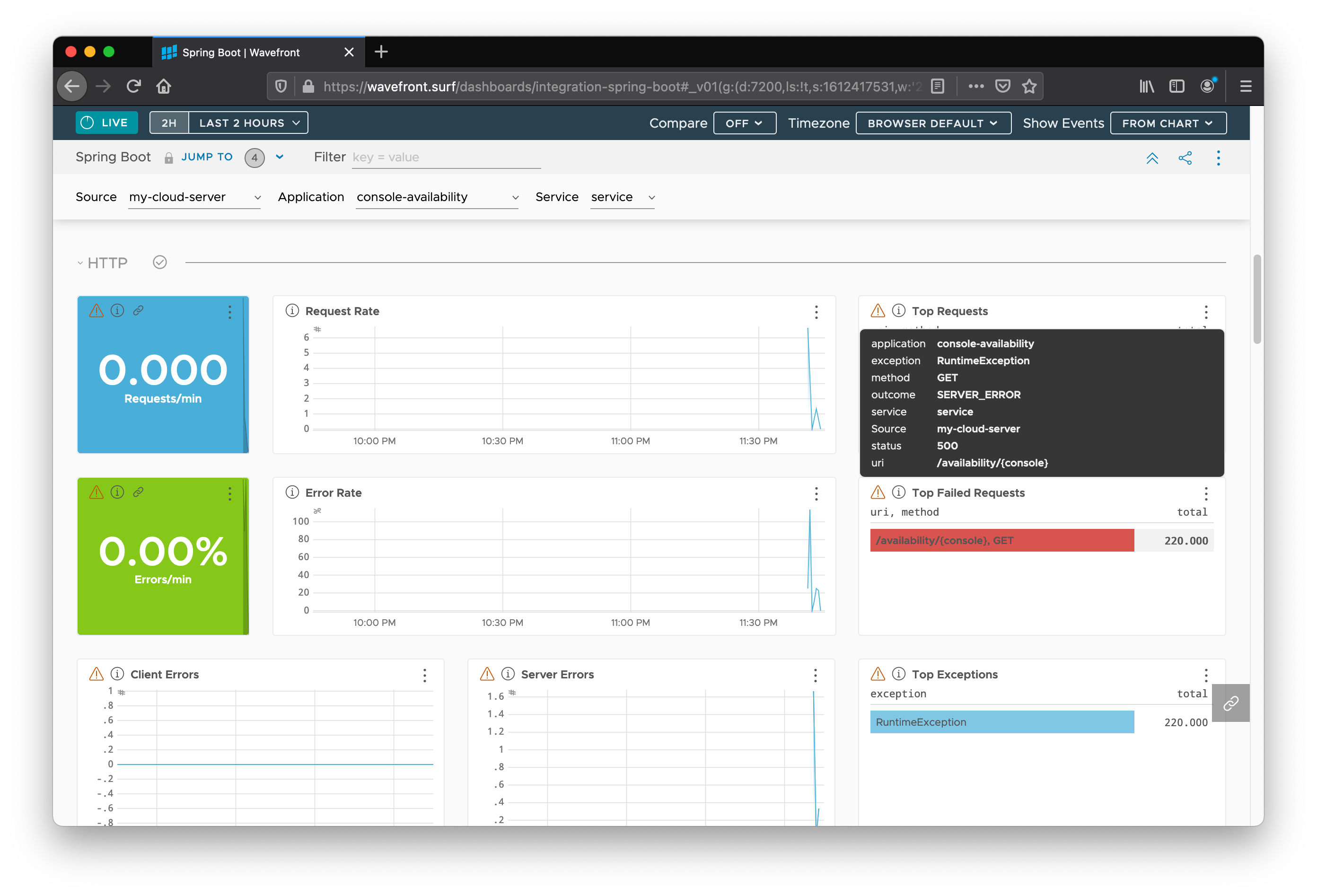
You can see useful information, such as the Top Requests, the Top Failed Requests, and the Top Exceptions encountered in the code.
Mouse over a particular type of request to get some details associated with each entry.
You can get information associated with the failing requests, such as the HTTP method (GET), service (service), status code (500), and URI (/availability/{console}).
These kinds of at-a-glance numbers are metrics. Metrics are not based on sampled data. They are an aggregation of every single request. You should use metrics for your alerting, because they ensure that you see all your requests (and all the errors, slow requests, and so on). Trace data, on the other hand, usually needs to be sampled at high volumes of traffic because the amount of data increases proportionally to the traffic volume.
We can see that the metrics collection has ignored the values for the {console} path variable in distinguishing the requests.
This means that, as far as our data is concerned, there is only one URI: /availability/{console}.
This is by design.
{console} is a path variable that we use to specify the console, but it could just as easily have been a user ID, an order ID, or some other thing for which there are likely many, possibly unbounded, values.
It would be dangerous for the metrics system to record high cardinality metrics by default.
Bounded cardinality metrics are cheap.
Cost does not increase with traffic.
Watch for cardinality in your metrics.
It is a little unfortunate, because, even though we know that {console} is a low-cardinality variable (there is a finite set of possible values), we cannot drill down into the data any further to see at a glance which paths are failing.
Metrics represent aggregated statistics, so, even if we broke down the metrics in terms of the {console} variable, the metrics still lack context around individual requests.
However, there is always the trace data. Click on the little breadcrumb/sandwich icon to the right of “Top Failed Requests”. Then find the service by going to Traces > console-availability.
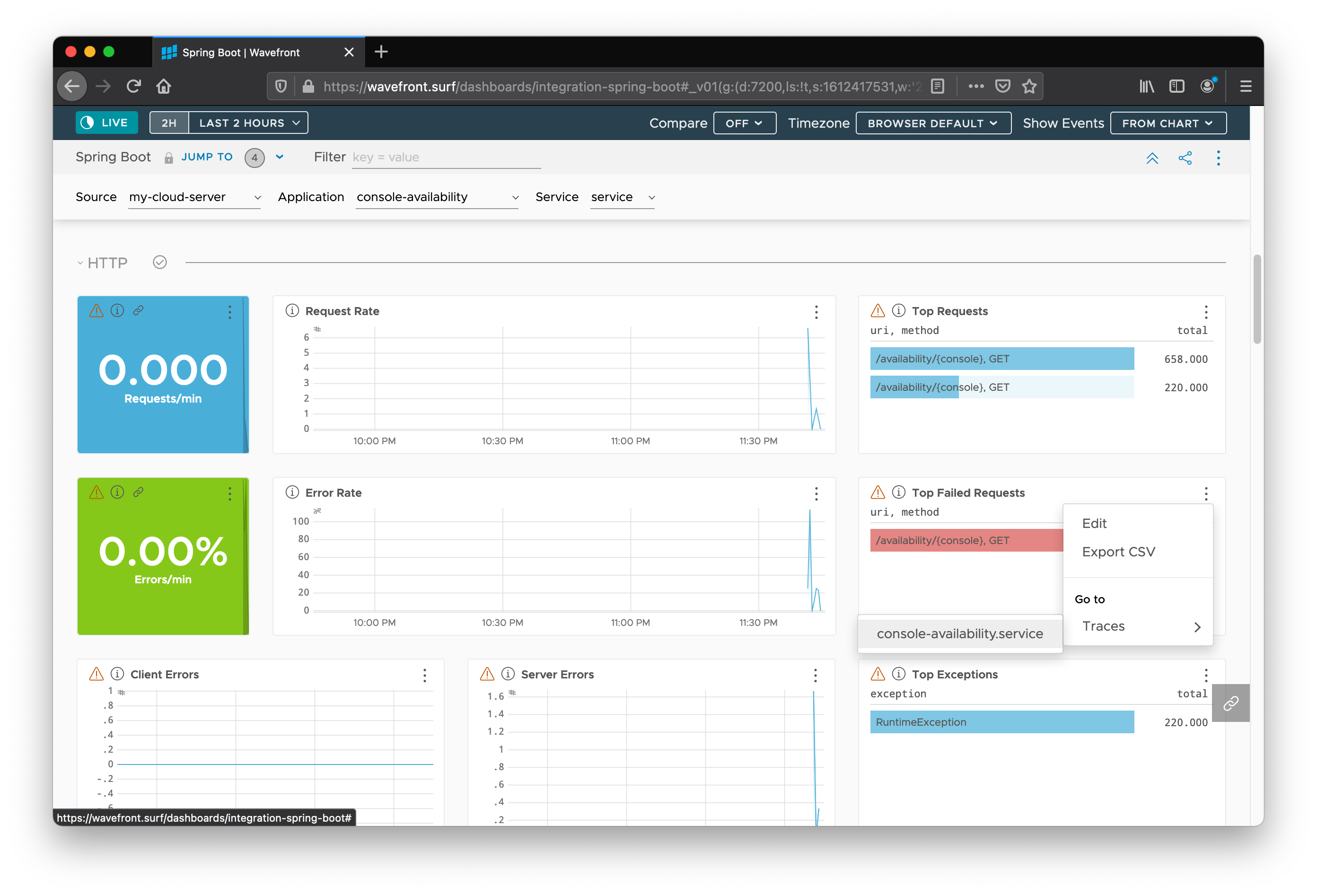
The following screenshot shows all the traces collected for the application (good, bad, or otherwise):
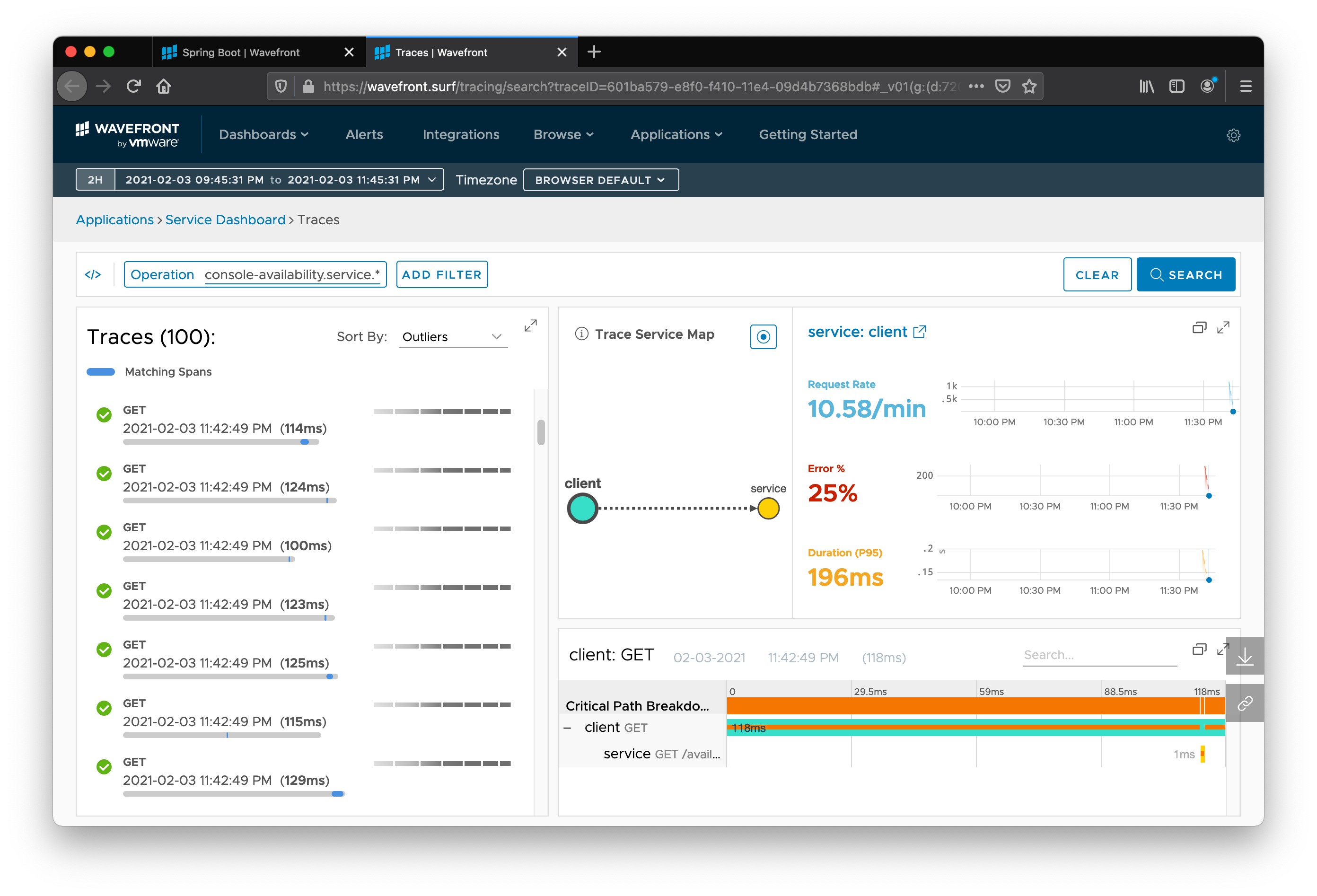
Now we can drill down into only the errant requests by adding an Error filter to the search. Then we can click Search. Now we can scrutinize individual errant requests. You can see how much time was taken in each service call, the relationship between services, and where the error originated.
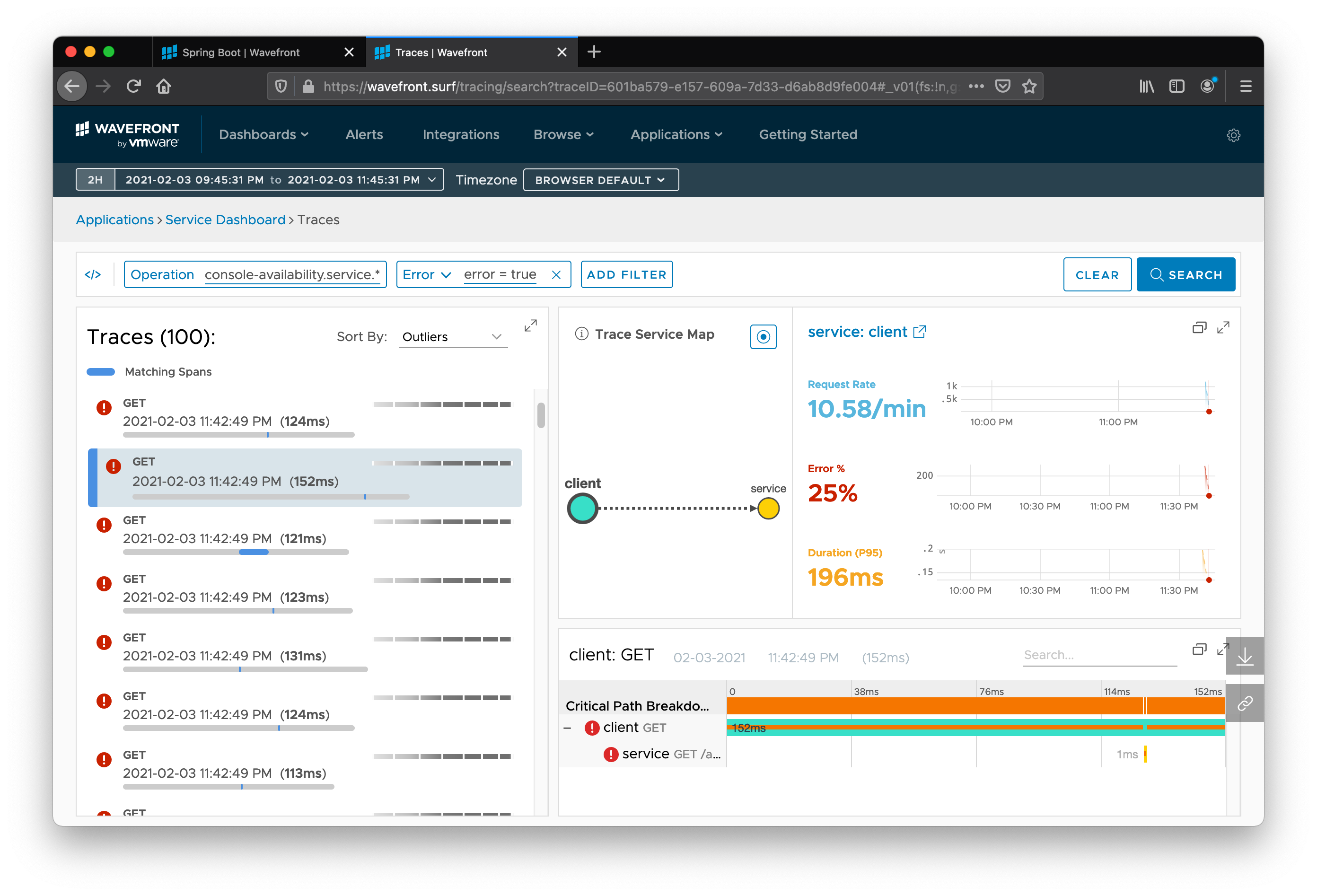
Click on the expand icon for the panel labeled “client: GET” in the bottom right. You can see each hop in the request’s journey, how long it took, the trace ID, the URL, and the path.
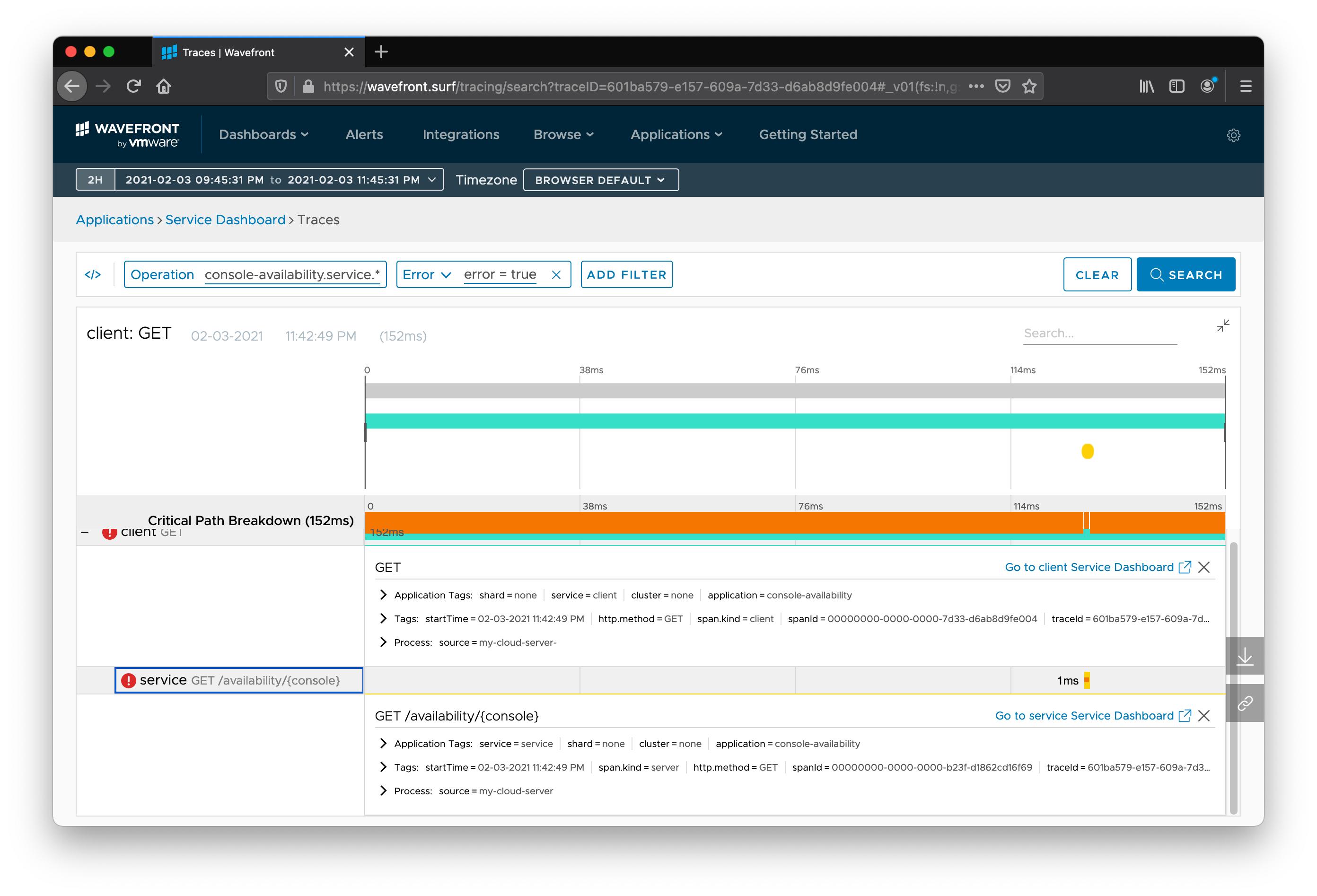
Expand the Tags branch under a particular segment of the trace, and you can see the metadata that Spring Cloud Sleuth automatically collected for you. A trace is made up of individual segments, called spans, that describe one hop in the request’s journey.
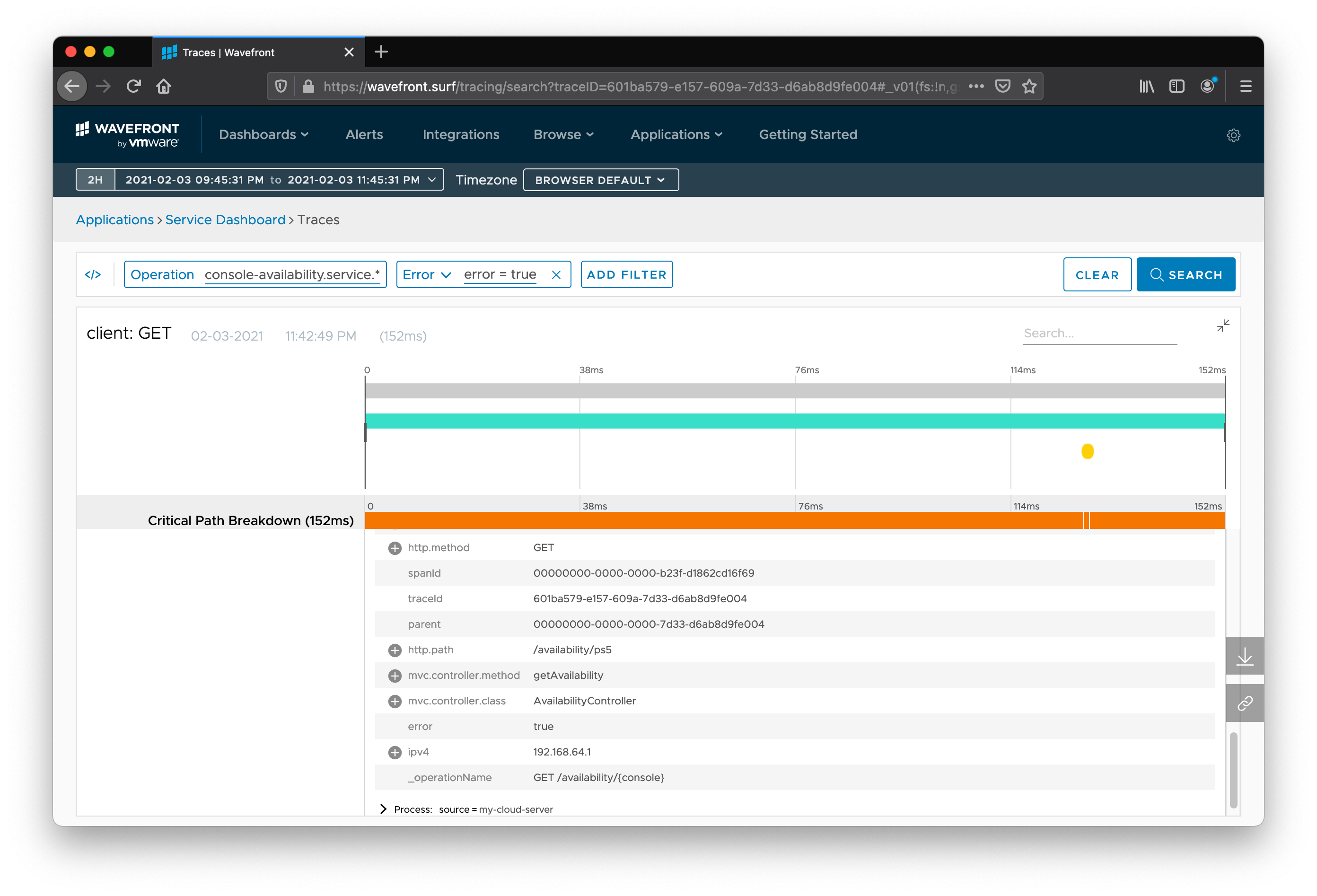
Often, developers are at least as interested in tracking business information as they are in tracking information like the number of hops. To that end, we can enhance our application to capture more data, which then appears in the Wavefront dashboard, where we can make decisions based on this information.
To enhance the application, we customize the data captured by Micrometer and Sleuth to drill down into a particular item of data: the type of console our site’s visitors have requested.
We can do so by using the {console} path variable.
The code already validates that the console’s value falls within a set of well-known consoles.
It is important that we validate the input before using it to ensure that the type of console is low cardinality.
You should not use arbitrary input (such as a path variable or query parameter) that could be high cardinality as a metric tag, though you could use high cardinality data as a trace tag.
Now, instead of determining the type of console from the HTTP path in the trace data, we can use a tag on the metrics and traces.
To make this change, we update the service to inject a SpanCustomizer, to customize the trace information.
We also update the service to configure a WebFluxTagsContributor, to customize the tags that are captured by Spring Boot and given to Micrometer. The following listing shows the modified application:
link:enhanced/src/main/java/server/ServiceApplication.java[role=include]
We want to explain why you want both metrics and tracing and how to use each for what. To start, you should consider the framing set up in Peter Bourgon’s Metrics, tracing, and logging blog post.
Tracing and metrics overlap in providing insight on request-scoped interactions in our services. However, some information provided by metrics and tracing is disjointed. Traces excel at showing the relationship between services as well as high-cardinality data about a specific request, such as a user ID associated with a request. Distributed tracing helps you quickly pinpoint the source of an issue in your distributed system. The tradeoff is that, at high volumes and strict performance requirements, traces need to be sampled to control costs. This means that the specific request you are interested in may not be in the sampled tracing data.
On the other side of the coin, metrics aggregate all measurements and export the aggregate at time intervals to define the time series data. All data is included in this aggregation, and cost does not increase with traffic (so long as best practices on tag cardinality are followed). Therefore, a metric that measures maximum latency includes the slowest request, and a calculation of error rate can be accurate (regardless of any sampling on tracing data).
You can use metrics beyond the scope of requests for monitoring memory, CPU usage, garbage collection, and caches (to name a few). You want to use metrics for your alerting, SLOs (service-level objectives), and dashboards. In the console-availability example, it would be an alert about an SLO violation that notifies us about a high error rate for our service. Alerts save you from constantly staring at dashboards and ensure that you do not miss something important.
Then, with both metrics and traces, you can jump from one to the other by using the metadata common to both. Both metrics and trace information support capturing arbitrary key-value pairs with the data called tags. For example, given an alert notification about high latency on an HTTP-based service (based on metrics), you could link to a search of spans (trace data) that match the alert. To quickly get a sampling of traces matching the alert, you can search for spans with the same service, HTTP method, and HTTP URI and that are above a duration threshold.
In short, data is better than no data, and integrated data is better than non-integrated data. Micrometer and Spring Cloud Sleuth provide a solid observability posture but can be configured and adapted to your business’s or domain’s context. Finally, while you could use Micrometer or Spring Cloud Sleuth with any number of other backends, we find Wavefront a convenient and powerful option.
Congratulations! You have a working metrics and tracing application that includes business data.